利用V8中的Math-expm1-typing漏洞
1 | Minus zero behaves like zero, right? |
喜欢浏览器漏洞利用。是破坏了我认为是每天运行的最复杂的软件之一. 在35C3 CTF 今年(和KJC + mhackeroni一起比赛,获得了第一名!) 这有一个Chrome挑战关于利用一个v8漏洞, Chrome的 JavaScript引擎. 这个错误在静态分析期间导致了不正确的输入, 在即时编译的代码中产生不正确的优化. 这真的很难触发: 没能在CTF中及时完成, 但我觉得很多人会对一篇完整的WRITEUP感兴趣. @_tsuro感谢你一开始就找到了漏洞,也感谢你所面临的巨大挑战, 还有ESPR的精彩CTF!
1 | Krautflare的员工是无服务器计算领域的最新突破。由于非常重视安全性,甚至将客户的工作负载相互隔离! |
The bug
浏览一下bug报告,它给出了一个粗略的演练,并尝试解析它。
1 | 该类型设置Math.expm1为Union(PlainNumber, NaN)。这缺少了-0 的情况: Math.expm1(-0) 返回 -0。 |
现代的JS引擎,如V8,对JS代码执行即时(JIT)编译,也就是说,它们将JavaScript转换为本机代码,以便更快地执行。在点火解释器执行一个函数多次后,该代码被标记为热路径,并由Turbofan JIT编译器编译。显然,我们希望尽可能地优化代码。因此,V8的优化管道大量使用了静态分析。感兴趣的最重要的属性之一是类型: 由于JavaScript是一种非常动态的语言,知道在运行时可以看到什么类型对于优化是至关重要的。
分析管道的一个组件是类型。它的作用是处理代码的中间表示中的节点,并根据可能的输入类型计算可能的输出类型。例如,一个常见的类型是range: 如果一个节点输出range(1,3),这意味着它可以有1、2或3的值。
在本例中,输入器表示Math.expm1的类型函数总是Union(PlainNumber, NaN) (see buggy typer.cc和operation-typer.cc). 这意味着输出要么是一个纯数字,要么是一个浮点NaN。plain - number类型表示除-0之外的任何浮点数。是的,浮点数有一个 - 0。然而,在运行时,Math.expm(-0)恰好是-0。因此,typer对类型做出了错误的假设。这种类型将传播到其他操作: 也许可以从中得到一个与安全相关的错误优化。
1 | 发现可以区分0和-0的有趣案例是除法,atan2和Object.is。在前两种情况中,输入代码不处理负0,因此只剩下Object.is。 |
下一个自然的问题是: -0在哪里会产生影响? 基本上,唯一有趣的情况是Object.is(Math.expm1(-0), -0)。如果检查一下数学的结果。expm1是-0,输入者认为答案总是假的,但它在运行时可能为真或假。
1 | 事实上,这个typer运行了3次: |
好吧,这里有一堆V8内部组件: 稍后再看。主要的一点是,该类型在管道中有多次运行,其间穿插着各种优化过程。如果typer过早发现在比较数学。expm1到-0,它只是将比较折叠成一个假常数(这并不完全发生在ConstantFoldingReducer中,稍后会更好地看到它)。这对我们来说是没有用的: 从功能的角度来看,代码是不正确的,但没有安全问题。另一方面,不想让输入器太晚发现-0比较,否则就不会得到正在寻找的错误优化。在我看来,这是整个行动的关键所在。
1 | 对象。此时,is调用可以用两种形式表示。作为ObjectIsMinusZero节点,如果先前的pass知道比较-0或作为SameValue节点。ObjectIsMinusZero的情况似乎并不有趣,因为类型信息没有在UpdateFeedbackType函数中传播。相同值的反馈类型会被传播,并且会被用于范围计算(现在有bug)。 |
对象。is调用以中间表示的SameValue节点开始。在被称为TypedOptimization的传递中,SameValue节点可以被简化为更特殊的节点(请参阅中ReduceSameValue) typed-optimization.cc). 在我们的例子中,因为我们在比较一些东西(数学。expm1 result)使用-0时,TypedOptimization将用专门的ObjectIsMinusZero替换相同的值。展望未来,我们要做破坏的输入通道被简化了 (simplified-lowering.cc). 这是管道中的第三种(也是最后一种)类型,它传播相同值节点的类型信息,但不传播专门的ObjectIsMinusZero节点的类型信息。需要类型传播来导致不正确的优化,因此希望避免转换为ObjectIsMinusZero: 像上面一样,不希望优化器过早地发现我们正在与-0进行比较。
1 | 然而,还有一个障碍你需要克服。使用朴素的方法,图中将有一个FloatExpm1节点。该节点输出一个浮点数,而相同值的节点需要一个指针作为输入,因此编译器将插入一个ChangeFloat64ToTagged节点进行转换。因为类型信息说输入永远不可能是-0,所以它不包括特殊的-0处理,我们的-0将被截断为常规的0。 |
Math.expm1操作将降低到FloatExpm1节点,该节点接受一个浮点数作为输入,并输出一个浮点数,该浮点数将成为SameValue的输入。然而,有两种可能的方法来表示浮点数: 作为“原始”浮点数,或作为标记的值(可以表示浮点数或对象)。FloatExpm1输出一个原始浮点数,但是SameValue接受一个带标记的值(因为它可以接受所有类型的对象)。因此,编译器插入一个ChangeFloat64ToTagged节点,以将原始浮点数转换为带标记的值。因为编译器认为ChangeFloat64ToTagged的输入永远不会是-0,所以它不会生成处理-0的代码。在运行时,来自Math的-0。expm1将被截断为0,破坏我们的努力。听起来像是个大问题…
1 | 但是,也可以将其改为Call节点,它将返回一个带标记的值,并且不会发生转换。 |
FloatExpm1只接受浮点数,但如果你尝试计算Math.expm1(“0”)(传递一个字符串),你会得到NaN,而不是某种错误。所以必须有一种方法让它接受非数参数。答案是V8包含了一个内置的Math.expm1实现,能够处理所有输入类型。如果可以强制Turbofan调用内置函数而不是使用FloatExpm1,会得到一个调用节点。不同的是,调用已经返回了一个标记的值,所以不需要ChangeFloat64ToTagged,并且-0不会被截断为0。
1 | 然后,可以在javascript数组中使用通常的检查边界消除和OOB RW结果。 |
这是正在寻找的错误优化。JavaScript数组访问由CheckBounds节点保护,该节点确保索引在数组边界内。如果优化器可以静态地确定索引始终处于范围内,那么它可以消除CheckBounds节点。将索引与对象的结果相联系的图像。is: 由于输入信息是关闭的,可以让分析器认为索引总是在范围内,而它在运行时可能是在范围外。优化器将错误地消除CheckBounds,使能够对JS数组进行OOB访问,可以使用它来构建更强大的开发原语。
重述bug
这是bug报告中的PoC:
1 | function foo() { |
这必须与d8 –allow-native-syntax 一起运行。第一次打印将输出true: 代码被解释并执行正确的操作。然后,优化foo并将输出更改为false: 优化器使用了错误的输入信息和折叠对象。是进了一个不变的假。
问题是,当在挑战的d8中尝试这个PoC时,它不起作用: 第二个打印仍然是正确的。可以使用turbolizer(v8/tools/turbolizer)来可视化Turbofan在每个优化阶段的IR,并找出发生了什么。通过传递-trace-turbo到d8,它将产生跟踪文件,可以导入Turbolizer。选择’simplified lowering’阶段(这是感兴趣的最后一个阶段),单击T来显示类型,然后单击四个展开箭头来显示所有节点,然后单击圆形箭头来布局它们。
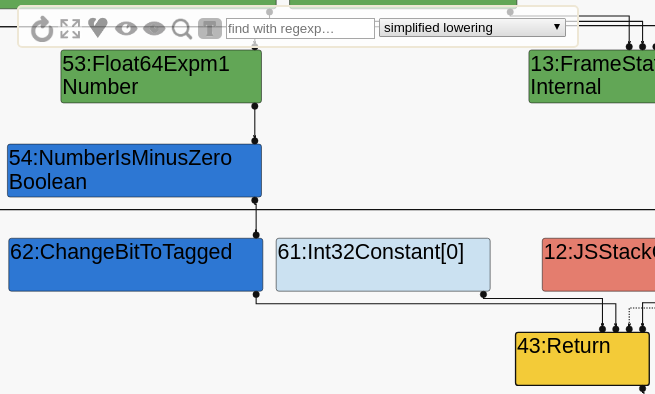
从图的这一部分中, 看到了所期望的: 一个FloatExpm1节点,它进入numberisminus 0,然后返回(转换为tagged后)。FloatExpm1的类型为Number,其中包括-0。不应该是PlainNumber或者NaN吗? 发生什么事情了? 原因可以在revert-bugfix-880207.patch文件中找到。重新引入错误。只打补丁typer.cc,不是operation-typer.cc: 因此,这个bug只在调用内置函数时出现,而不是在FloatExpm1上。反正也得生成call,现在就开始吧。
FloatExpm1是一个针对数字输入的优化节点: 编译器推测输入将是一个数字。如果它在运行时确实是一个数字,很好,它将继续执行优化的代码。如果它不是一个数字,优化后的函数将退出解释器: 这个过程称为反优化。解释器将使用内置,它可以接受所有类型。下一次编译函数时,Turbofan会得到反馈信息,通知它输入并不总是一个数字,并且会产生一个对内置函数的调用,而不是FloatExpm1。
我们来做一下。将使用循环来触发编译,而不是本地语法,因为在实际运行漏洞时不会使用它。
1 | function foo(x) { |
这将打印为false。在运行它时,您将注意到函数现在编译了两次。可以添加–trace-deopt标志来通知取消优化。首先,foo将被解释。一段时间后,假设x是一个数字,就会对它进行编译和乐观优化。第一次调用编译后的函数(x作为字符串)时,得到了反优化:
1 | [...] |
它在更新类型反馈,告诉Turbofan不要把x当成一个数字。第二次编译函数时,Turbofan会生成一个对内置函数的调用。会看到现在有两个Turbolizer痕迹。最近显示的是一个类型为PlainNumber或NaN的呼叫节点,正如所期望的那样。
一开始你可能会问foo(0)的目的是什么。老实说,还没有完全搞清楚: 有人可能认为它需要提供数字反馈,但可以在console.log之后移动它,它仍然可以工作(Turbofan在这种情况下默认是乐观的)。然而,如果删除它,它将不再工作。相信这和主体中foo的一些内联有关,但是肯定想知道更多关于这方面的信息。有什么主意就告诉给我!
复制这个错误。下一步: 在JS数组上获得OOB。
触发OOB访问
如前所述,其思想是使数组的索引依赖于对象的结果。这样分析器就会假定索引总是在范围内。例如,考虑foo:
1 | function foo(x) { |
正在尝试读取OOB,因为很容易看到它。通过使用赋值,它可以轻松地成为一个写入OOB。如果b为false,则访问索引0: 因为a的长度是已知的,所以优化器可以确定这是静态的。如果b为真,访问索引1337,这是越界的。优化器认为b只能是假的,所以它将消除边界检查。我不会在这个例子上浪费时间: 很明显,b将被折叠为一个常量false(就像在PoC中一样),所以总是访问索引0。
可以通过将-0作为参数来添加间接变量:
1 | function foo(x, y) { |
这次得到了undefined:
1 | ;;; 反优化在 <poc3.js:4:13>, 界外 |
不是折叠了,但也不会去掉边界检查。检查一下Turbolizer(简化降低).
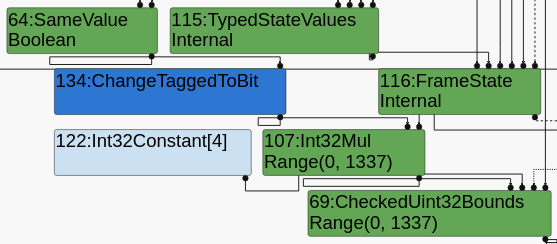
保留了一个SameValue节点,但它的类型是布尔型而不是单例false型。这意味着分析者认为它可能是真的也可能是假的。这会传播,为索引提供一个范围(0,1337),这显然不允许边界检查消除。往回看,发现y作为[2]节点的形参,具有NotInternal类型。这意味着分析器不知道y的类型,确切地说,它不知道它总是-0。
在这一点上,决定有条不紊。学习一下Turbofan管道(见pipeline.cc)并发现:
最后阶段Object.is为false可能发生: 在此之前,不想让分析器知道正在与-0进行比较。
类型发生的最后一个阶段: 希望分析器知道在此之前与-0进行比较,以便信息传播。
最后一轮输入是在简化的降低阶段。这是到那时为止的Turbofan优化管道:
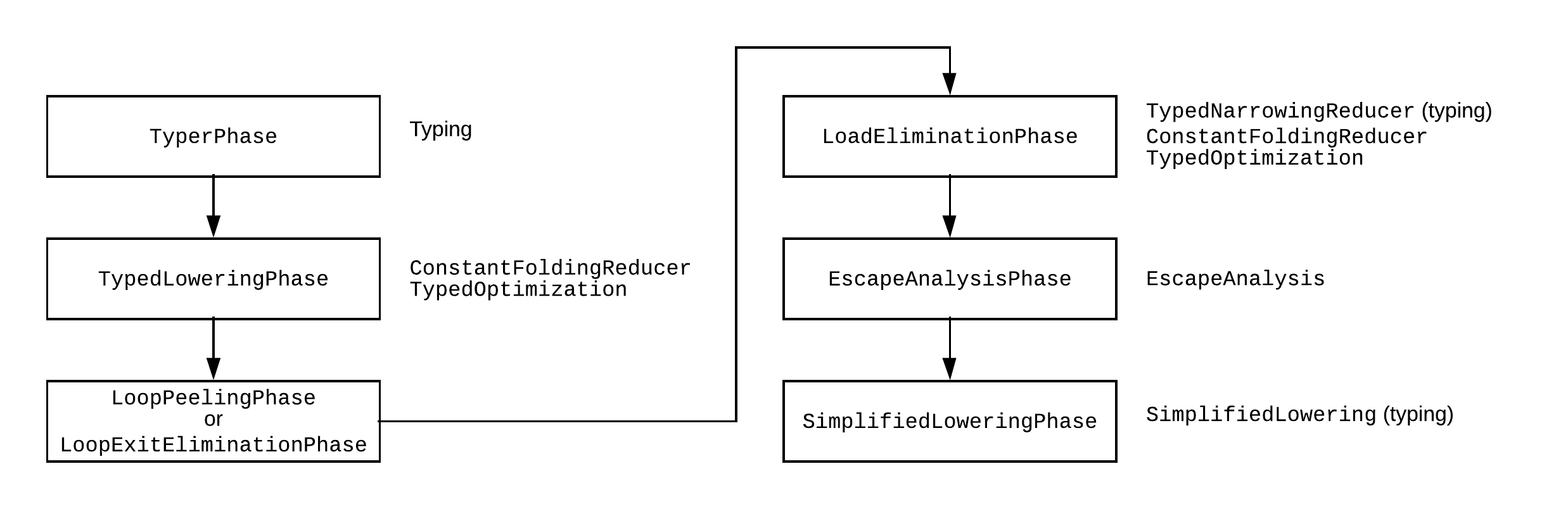
每个阶段都有很多传递,在右边报告了一些相关的,标记了输入传递发生的地方。
看看折叠是如何发生的。ConstantFoldingReducer将传播-0常量(例如,如果使用的变量的常量值为-0)。正如之前观察到的,TypedOptimization将把与常量-0比较的相同值节点减少为ObjectIsMinusZero节点。稍后在管道中,simpledlowering传递可以在ObjectIsMinusZero节点上执行进一步的缩减 (simplified-lowering.cc). 由于math.expm1静态类型不包括-0, simplefedlowering会将ObjectIsMinusZero节点折叠成一个假常量。因此,在输入UpdateFeedbackType时,它将从SameValue节点传播类型信息,但不会进一步减少它们。保持相同的值意味着,直到最后一次类型优化之后,分析器才会知道正在与-0进行比较。
这留下了两个选择。要么在转义分析期间获得信息,要么在类型运行之前进行简化的降低过程中获得信息。简化的降低还为值选择机器表示,并在输入之前反向传播表示反馈。这就是在行动中搞砸的地方。虽然很熟悉V8的代码库,但要弄清楚这篇文章中列出的所有内部结构很累。在查看管道时,大脑跳过了escape分析(可能是因为它被包裹在一个条件中),认为必须使用简化的降低。剧透警告: 你不会有任何进展的。教训: 通过橡皮鸭重新运行你的系统方法。
快速复习一下逃逸分析。这段代码:
1 | function f() { |
显然,它可以重写为:
1 | function f() { |
虽然o必须是一个具体的堆分配,但o_a可以被非物化,并在堆栈或寄存器变量中转换(更有效),或常量折叠到return语句中。
现在在中间添加一个对函数g的调用:
1 | function f() { |
优化不再有效,因为g可以在全局变量中保存对o的引用。因此,不能在堆栈分配中转换o,因为全局引用的寿命会比堆栈变量长,而堆栈变量只有在f的作用域是活的时才有效。o已经逃离了f的范围: 逃离分析的目标是识别哪些对象逃脱了,这样非逃脱的对象就可以被去物化。
这意味着,在escape分析运行之前,分析器将o.a视为通过对象引用访问一个字段:它不知道它的类型,因为它不能对o做出假设。这对我们来说是完美的。代码比语言更响亮:
1 | function foo(x) { |
现在是Object.is的第二个参数是o中的字段mz。在转义分析之前,分析器不知道它是一个常量-0,所以TypedOptimization将保持一个相同的值节点。escape分析发现,o不会逃脱,并将它去物化并传播常数,所以在简化降低之前,得到一个相同的值,其常数为-0。然后,最后一次输入运行将确定SameValue始终为false,并传播此信息,从而消除边界检查。实际上,如果运行这段代码,它将返回“奇怪的”值,因为它从堆中读取超过数组边界的内存(尝试使用索引)。
太好了,有机会了! 不过,这仅仅是一个开始: 需要在此基础上构建几个原语。
JavaScript 利用原语
JavaScript的利用遵循某些常见的模式。在这个漏洞的基础上,漏洞作者构建了更抽象的原语,这在损坏的内存中提供了更多的自由。
两个常见的原语是addrof和fakeobj。addrof原语接受一个对象,并给我们该对象的内存地址。这是必需的,因为现代系统采用了ASLR(地址空间布局随机化),因此内存区域(代码、堆、库、堆栈……)的位置是随机的,攻击者是不知道的。此外,JS引擎的堆非常拥挤,因此预测对象的地址是脆弱的。fakeobj原语获取一个内存地址,并返回由该内存支持的对象引用。通过获取由攻击者控制的缓冲区支持的引用,它可以用来制作假JavaScript对象。
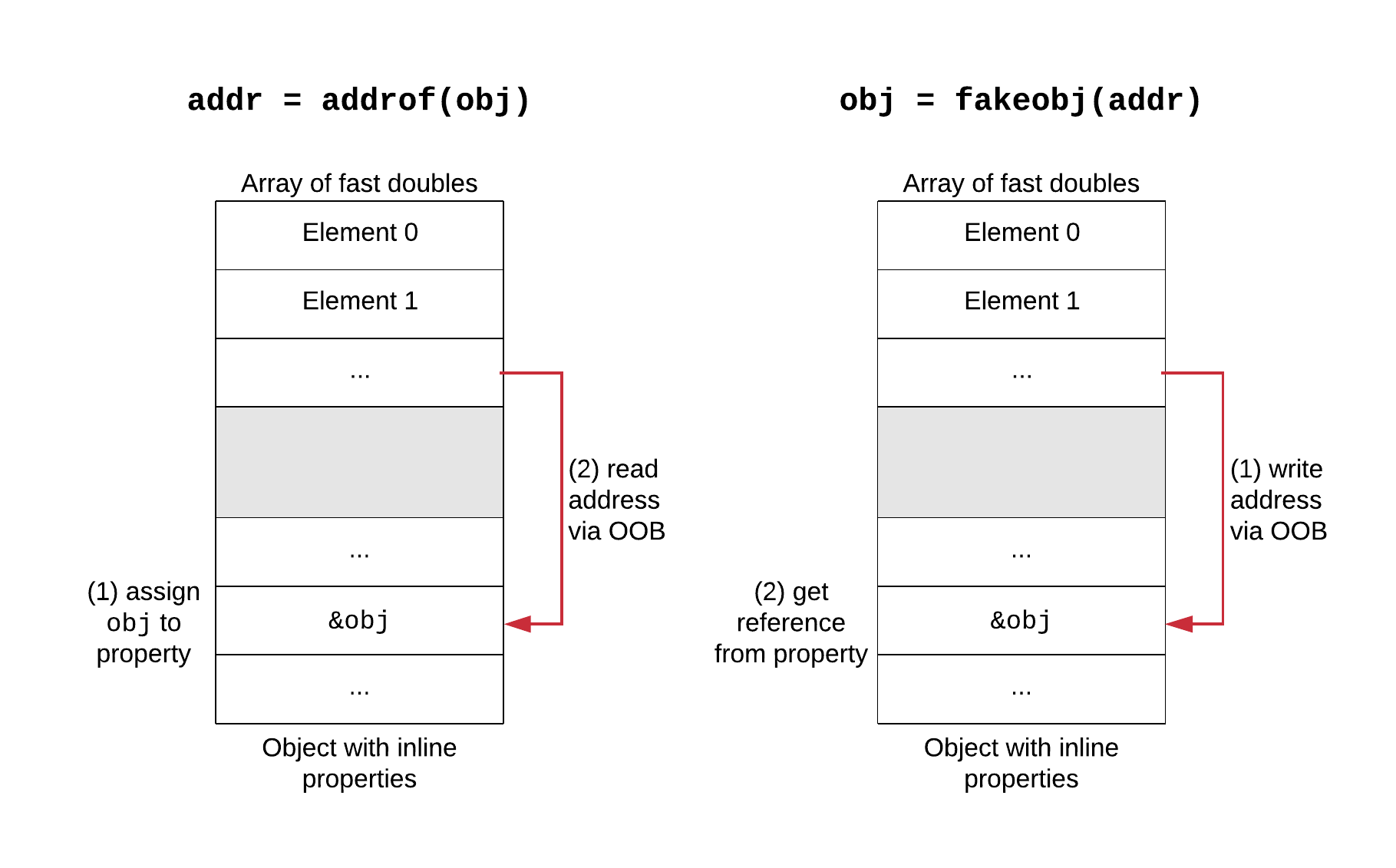
当bug是OOB时,通常的设置是有一个double数组A,可以在其上执行OOB访问,并在内存中放置一个具有内联属性(或对象数组)B的对象A之后。假设攻击者知道两者之间的偏移量(可以在运行时找到),因此A上的OOB可以用来访问B的内存。诀窍在于,通过内存的访问是双精度访问(假设元素是不打包的快速双精度访问),而B包含指向对象的指针。为了实现addrof,将对象赋值给B的属性: 这将把对象的地址存储在B的内存单元中。然后,使用A上的OOB将该内存单元读为double,并将其解码为整数(它们的内存表示不同)。fakeobj原语是对称的。将对象的地址编码为double,然后使用a上的OOB将其存储到B的内存中: 现在B的属性包含了对假对象的引用,可以返回它。
最强大的原语是任意读/写,它允许在任何内存地址读或写数据。它通常是通过 ArrayBuffer. 在内部,后备缓冲区是行外存储的,ArrayBuffer对象包括一个指向它的指针和它的大小。因此,攻击者控制的ArrayBuffer可以指向内存中的任何地方。这对于普通数组也是可能的,但是ArrayBuffer还有另一个优点: 它可以覆盖typed arrays 和 DataView 可以很容易地操作原始内存。ArrayBuffer可以通过两种方式构建: 使用一些其他的原语(例如,稳定OOB)来破坏现有ArrayBuffer的指针和大小,或者通过fakeobj原语来构建一个伪ArrayBuffer。
回到bug。理想情况下,为了正确地封装OOB,需要一个接受数组、索引并执行OOB(读或写)的函数。取任何索引都很简单,只需要让输入者相信你在用一个数字乘以b(例如,按位和用数字)。MAX_SAFE_INTEGER乘法之前)。然而,发现扩展到任何数组都是非常脆弱的。如果有一种方法可以让它工作,不会感到惊讶,但发现很难保持输入信息的完整性,并让优化器消除边界检查,这也是因为在优化流程中已经很晚了。相反,决定接受这个OOB转瞬即逝的特性,并且只使用它一次来构建一个更可靠和可重复的OOB。
想法是这样梳理堆将在应用错误的数组后分配三个对象(将其称为origin数组):
- 一个快速双精度数组,称之为OOB数组;
- 具有内联属性的对象,受害者对象;
- ArrayBuffer,受害者缓冲区.
将保留对这三个对象的全局引用,以备以后使用。两个受害者的顺序不重要,只要他们在OOB数组之后。使用这种布局,可以使用原始数组OOB将OOB数组的长度破坏为一个较大的值。现在OOB数组通过普通的元素访问为我们提供了可重复的OOB。然后,可以使用面向对象的方法实现受害者对象的addrof原语,使用面向对象的方法实现受害者缓冲区的任意读/写。不需要fakeobj。
构建原语
这就是我们所追求的堆布局:

每个JavaScript数组是由两个堆对象: JSArray, 代表实际的JavaScript数组对象, 和一个FixedArray内部固定大小的数组类型用作后备存储器数组元素(这适用于数组没有或很少有洞,否则,就会降级为一个字典对象)。两者都有长度字段。对于JSArray,它是实际的JavaScript长度(在数组访问期间检查)。对于FixedArray,它是后备存储的长度,可以大于JavaScript数组的大小(在过度分配的情况下)。JSArray和FixedArray的顺序可能不同,但动态地找到它们,因此这无关紧要。
V8的堆是由一个bump分配器和一个分代垃圾收集器管理的(简单介绍, 例如,here). 作为一个bump分配器,对象在内存中的顺序遵循分配的顺序,只要GC不移动太多的东西,所以它应该只是按照顺序分配对象。为了提高可靠性,将在堆上喷洒大量对象,并保持对这些对象的引用,以防止GC收集它们。这应该有助于线性化堆。
事实上,这种spray也是利用bug的一种副作用。必须在原点数组之后分配OOB数组和受害者,但在访问原点数组之前破坏OOB数组的长度。因此,分配必须是欺骗类型的函数的一部分(前面例子中的foo)。这将在循环中被多次调用,以强制JIT编译,因此将得到大量的分配。尝试使用一个标志来只分配在最后一次调用(-0),但这搞砸了优化,无论如何想要一个spray。
这是我们的原语的完整计划:
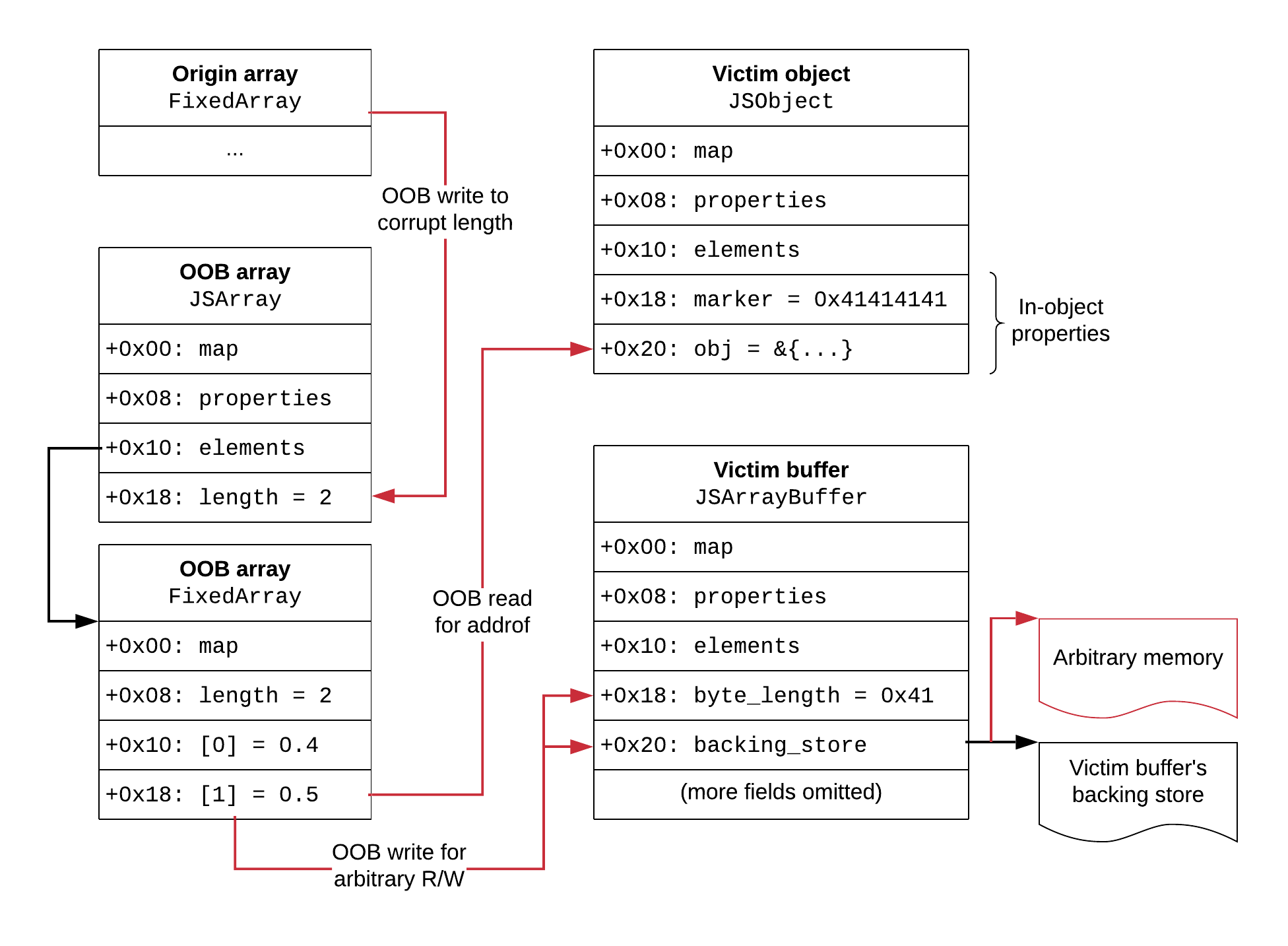
使用输入错误通过原始OOB破坏了OOB数组的长度。在那之后,就可以自由了: OOB数组现在可以让我们在任何需要的时候对其他对象进行OOB访问。这种构造只利用了一次bug,这是可取的,因为围绕它编写代码并不容易。OOB数组将是唯一长度为2的数组,它允许通过使用原始OOB在内存中扫描值2来动态地找到它的位置。这比使用固定偏移量更可靠,并且可以容忍堆布局的一些变化。注意,长度2在JSArray和FixedArray中都存在,但感兴趣的是查找和破坏JSArray的长度。OOB数组(0.4和0.5)的元素将作为标记来区分JSArray和支持的FixedArray。
一旦OOB数组被损坏,通过OOB对受害者对象构建addrof,并通过OOB对受害者缓冲区进行任意读/写,方法是更改其指向所需地址的反向指针。对象中有标记: 在受害者对象中有一个值为0x41414141的内联属性,在受害者缓冲区中有一个大小为0x41的属性。通过这种方式,可以通过从OOB数组读取这些标记来扫描内存来定位它们。
实现这个。将使用三个全局数组(arrs、obs和bufs)来存储喷洒的实例。为了处理64位整数,将使用实用程序this exploit by Samuel Groß.
函数照常启动,通过触发输入错误:
1 | let o = {mz: -0}; |
然后分配对象,并将它们保存到全局数组中:
1 | let a = [0.1, 0.2, 0.3, 0.4]; // origin array |
现在可以搜索OOB数组,破坏JSArray的长度,这样就完成了:
1 | let new_size = (new Int64("7fffffff00000000")).asDouble() |
仔细看看这个。正如前面所说的,不能让它只在最后的-0调用时使用一个标记来破坏,所以它的结构在优化循环期间是无害的。然而,这将浪费循环,所以将循环迭代降低到10k(仍然足够优化),以防止它变得太慢。
从第一个OOB索引(4)迭代到某个任意的限制(20)。当在当前索引处找到JSArray的长度时,布尔值good将为true。首先,检查当前索引处的值是否为2。由于对齐和字大小的差异,长度左移了32位。值2可以出现在两个地方: JSArray长度和相应的FixedArray长度。对JSArray感兴趣。知道FixedArray的长度后面跟着第一个元素(0.4),所以通过查看下一个索引,可以确定是找到了JSArray还是FixedArray支持。最后,有两件事会发生a[bigood] = new_size:
如果在优化循环中(b为false)或者没有查看JSArray的长度(good为false),它将赋值给[0],这是无害的;
如果查看JSArray的长度,它将被设置为一个较大的值 (0x7fffffff).
一旦从-0调用返回,将(希望)在arrs中有一个长度损坏的数组,并且可以找到它:
1 | let oob_arr = null; |
现在是时候使用OOB数组来查找受害者对象,以及它的obj属性所在的OOB数组中的索引了。这是一个两步的过程。首先,寻找0x41414141标记属性,并将其更改为一个不同的值(0x42424242)。下一个索引是obj属性。
1 | let victim_obj = null; |
由于有不同的标记,可以在obs中找到受害者对象(通过oob_arr的obj索引是受害者obj_obj_idx_obj):
1 | for (let i = 0; i < objs.length; i++) { |
同样的两步过程也适用于寻找受害者缓冲区。这一次,寻找0x41长度,并将其更改为不同的大尺寸以进行标记(并不需要它那么大,但也没有什么坏处)。后备存储指针紧接在长度之后。
1 | let victim_buf = null; |
然后通过检查长度找到标记的受害者缓冲区:
1 | for (let i = 0; i < bufs.length; i++) { |
此时,已经拥有了构建原语所需的一切。例如,这是addrof:
1 | addrof(obj) { |
它将对象引用赋值给受害者对象的obj字段,然后通过OOB数组读取指针。注意,V8中的指针是被标记的,以区别于小整数: 最低位总是被设置的,所以减去1就得到真正的地址。
这是任意的读/写:
1 | read(addr, size) { |
这两种方法的第一行都使用OOB数组来更改受害者缓冲区的后备存储指针。然后,他们在ArrayBuffer的顶部创建一个Uint8Array以字节形式访问内存,并执行读/写操作。
在读写之外,还可以很容易地编写其他专用的原语,以方便使用, 把这个问题留给读者来解决。对于稍后将使用的代码执行漏洞,建议实现read32(读取32位整数)、read64(读取64位Int64)和write64(写入64位Int64)。
我们的原语现在已经实现并且稳定了。开始执行代码。
代码执行
显然,NX是启用的,所以不能在 “普通” 内存区域做代码注入。从前,V8的JIT代码页拥有RWX权限。因此,可以简单地结合addrof和read来获取编译函数的代码地址,通过write用shellcode覆盖它,然后调用该函数。不幸的是,现在已经不是这样了compilation flag默认情况下,它将通过在RW和RX之间交替编写保护代码。
顺便说一句,这个标志实际上可以在运行时更改(有一个可写的副本)。能做到吗? 简短的回答: 不要浪费时间,有更好的方法(见下文)。长答案(需要V8内部知识): 标志缓存在堆实例中,可以通过MemoryChunk定位,可以通过从堆对象逐页向后扫描来找到有效的头。然而,更改标志将改变CodeSpaceMemoryModificationScope的语义,并且编译器试图写入RX内存时可能会崩溃。我想,如果让它分配一个新的MemoryChunk(可能通过使用大型代码对象空间?),它可能会工作,但还必须担心后台编译和反优化, 在我看来很乱。
显然,唯一的选择是代码重用攻击(例如,ROP)。这将需要一个堆栈枢轴,或者找到一个合适的堆栈帧来损坏。我很懒,我喜欢更好的方式。幸运的是,JavaScript并不是V8中唯一需要编译的语言: 还有WebAssembly.write-protect flag 默认为false,因此编译后的WebAssembly代码为RWX。
可以编译一些WebAssembly代码,并通过addrof获得导出函数的JSFunction对象的地址:
1 | let wasm_code = new Uint8Array([...]); |
现在,必须从这个JSFunction中获取编译后代码的地址。通过查看JS-to-Wasm包装器是如何内置的,可以找到答案wasm-compiler.cc (并经过一些调试)。从JSFunction中,必须读取SharedFunctionInfo指针。然后,从共享的信息中,可以得到一个指向函数data的指针,它的类型是wasmexporttedfunctiondata。这里有需要的两个字段: 指向WasmInstanceObject的指针和函数索引。从WasmInstanceObject中,可以获得跳转表起始点的地址,当将该地址添加到函数索引时,将给出函数跳转表项的地址。它位于RWX代码内存中,是函数的入口点。将保留计算偏移量和将读取链写入阅读器(必须查看一些标题,这并不困难)。
一旦有了入口点地址,可以向它编写shellcode并调用该函数:
1 | let shellcode = [0xcc, 0x48, 0xc7, 0xc0, 0x37, 0x13, 0x00, 0x00]; |
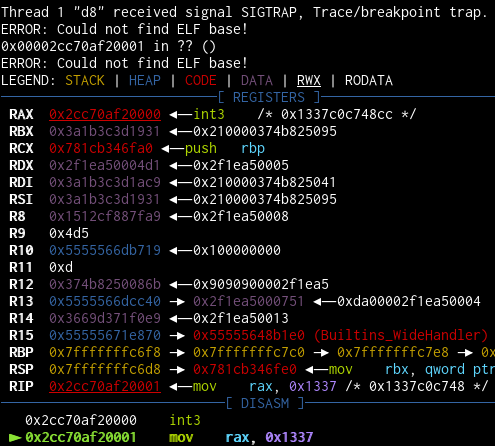
完美的结局.
Conclusion
这是我触发过的最严重的漏洞。这个漏洞本身是相当标准的 (关于最后一部分,我以前没有见过公开使用WebAssembly,但我相信其他人知道它),但是愚弄typer绝对是一次冒险。离开的时候,对V8的内部结构有了一定的了解,虽然仍然有限,但已经比刚开始的时候好多了。希望您喜欢阅读这篇文章,尽管它相当长。一次又一次,@_tsuro对于第一次发现并利用这个bug: 这是一项可怕的工作!
译自
- Exploiting the Math.expm1 typing bug in V8