v8中简单bug的复杂漏洞
介绍
这篇文章探讨的是Project Zero Issue 2046,一个看似不可利用和简单的bug,结果却以非常复杂的方式被利用。
Sergey Glazunov最近在Project Zero bugtracker上披露了2046号问题。
这个问题描述了当开发者决定使用新的Torque语言重新实现两个CodeStubAssembler (CSA)函数时引入的一个bug。这两个函数在JavaScript中用于创建新的FixedArray和FixedDoubleArray对象,尽管乍一看实现看起来有效,缺少一个关键组件: 一个最大长度检查,以确保新创建的数组的长度无法不经过一个预定义的上限。
这bug看起来并不是可利用的(当然,最初如果是自己,就会以为它是unexploitable),但如图所示错误报告, Sergey用TurboFan的typer来获得一个非常强大的exploitation原语: 数组的长度远远大于它的容量。这个原语为攻击者提供了V8堆上的越界访问原语,这很容易导致代码执行。
现在对bug跟踪器中提供的复杂再现案例进行根源分析,看看如何从如此简单的bug中实现如此强大的原语。
设置
如果你想跟随本文,你需要构建V8 8.5.51版本 (commit 64cadfcf4a56c0b3b9d3b5cc00905483850d6559). 按照此指南获取构建说明. 我推荐使用完整的符号来构建 (修改参数。gn并添加symbol_level = 2这一行).
从x64.release下,可以使用以下命令来编译没有编译器优化的release版本(逐行调试优化后的二进制文件有时会非常烦人):
1 | find . -type f -exec grep '\-O3' -l {} ";" -exec sed -i 's/\-O3/\-O0/' {} ";" -ls |
如果想要跟随这篇博文中的一些代码示例,建议构建正常的release版本(启用编译器优化)。如果没有这些优化,有些示例将需要非常长的时间才能运行。
从上面链接的bug跟踪器中获取概念的证明。
讲一点历史
为了理解为什么首先引入这个错误,首先必须了解一点CodeStubAssembler的工作方式,以及为什么要创建Torque来替代它。
在2017年之前V8
在2017年之前,许多JavaScript内置函数(Array.prototype.concat, Array.prototype.map, etc)。虽然这些函数使用了TurboFan (V8的投机优化编译器,后面会详细解释)来尽可能地提高性能,但它们的运行速度不如用本地代码编写的那么快。
对于最常见的内置函数,开发人员会用手工编写的程序集编写非常优化的版本。这是可行的,因为ECMAScript规范(示例)对这些内置函数的描述非常详细。然而,有一个很大的缺点: V8瞄准了大量的平台和架构,这意味着V8开发者必须为每个架构编写和重写所有这些优化的内置函数。由于ECMAScript标准在不断发展,新的语言特性也在不断标准化,因此维护所有这些手写的汇编变得极其繁琐且容易出错。
遇到这个问题后,开发人员开始寻找更好的解决方案。直到将TurboFan引入V8引擎,他们才找到了解决方案。
THE CODESTUBASSEMBLER
TurboFan为低级指令带来了跨平台的中间表示(IR)。V8团队决定在TurboFan之上建立一个新的前端,称之为CodeStubAssembler。CodeStubAssembler定义了一种可移植的汇编语言,开发人员可以使用它来实现优化的内置函数。最重要的是,可移植汇编语言的跨平台特性意味着开发人员只需要编写每个内置函数一次。所有受支持的平台和架构的实际本地代码都留给了TurboFan来编译。可以在这里阅读更多关于CSA的信息。
虽然这是一个很大的改进,但仍然有一个小问题。用CodeStubAssembler的语言编写最优代码需要开发人员在头脑中携带大量专业知识。即使掌握了所有这些知识,仍然存在许多经常导致安全漏洞的重要陷阱。这使得V8团队最终编写了一个他们称之为Torque的新组件。
TORQUE
Torque是一种构建在CodeStubAssembler之上的语言前端。它拥有类似于typescript的语法、强大的类型系统和出色的错误检查功能,这一切都使它成为V8开发者编写内置函数的绝佳选择。Torque编译器使用CodeStubAssembler将Torque代码转换为有效的汇编代码。它极大地减少了安全漏洞的数量,同时也减少了新的V8开发者以前在学习如何用CSA汇编语言编写高效内置函数时所面临的陡峭学习曲线。可以在这里阅读更多关于Torque的内容.
THE REASON FOR THE BUG
因为Torque仍然是相对较新的,仍然有相当数量的CSA代码需要在其中重新实现。这包括处理创建新的FixedArray和FixedDoubleArray对象的CSA代码,这是V8中的“快速”数组(“快速”数组有连续的数组后备存储,而“慢”数组有基于字典的后备存储)。
2046号问题中的实际错误源于开发人员决定在Torque中重新实现这个数组创建内置函数。不幸的是,重新实现错过了一个关键的安全检查,这导致了一个可利用的条件。
The bug
开发人员重新实现了CodeStubAssembler::AllocateFixedArray 函数两个Torque宏,一个用于FixedArray对象,另一个用于FixedDoubleArray对象:
1 | macro NewFixedArray<Iterator: type>(length: intptr, it: Iterator): FixedArray { |
如果将上述函数与CodeStubAssembler::AllocateFixedArray变量进行比较,就会注意到最大长度检查缺失。
NewFixedArray应该确保返回的新FixedArray的长度低于FixedArray::kMaxLength,即0x7fffffd或134217725。
同样,NewFixedDoubleArray应该根据FixedDoubleArray::kMaxLength检查数组的长度,即0x3fffffe或67108862。
在了解如何处理这个缺失的长度检查之前,先了解一下Sergey是如何触发这个错误的,因为这并不像创建一个大于kMaxLength的数组那么简单。
v8中的数组
为了理解概念证明,需要了解更多关于V8中数组是如何表示的。如果已经知道这是如何工作的,可以直接跳到下一节。
内存中的数组
以数组[1,2,3,4]为例,在内存中查看它。可以运行带有–allow-native-syntax flag的V8,创建数组,并使用%DebugPrint(array)来获取它的地址。使用GDB查看内存中的地址。用一个图表来代替。
当在V8中分配一个数组时,它实际上分配了两个对象。注意每个字段的长度都是4字节/32位:
1 | A JSArray object A FixedArray object |
JSArray对象是实际的数组。它包含四个重要的字段(以及其他一些不重要的字段)。这些是:
map指针 —— 它决定了数组的“形状”。具体来说,它确定数组存储的元素类型,以及它的后备存储对象的类型。在本例中,数组存储整数,后备存储是一个FixedArray。
属性指针 —— 该指针指向存储数组可能具有的所有属性的对象。在本例中,数组除了长度之外没有任何属性,长度以内联方式存储在JSArray对象本身中。
元素指针 —— 它指向存储数组元素的对象。这也被称为后备存储。在本例中,后备存储指向FixedArray对象。稍后再详细介绍。
数组长度 —— 这是数组的长度。在Sergey的概念证明中,这是覆盖到0x24242424的长度字段,然后允许读和写越界。
JSArray对象的elements指针指向后备存储,这是一个FixedArray对象。这里有两点需要记住:
FixedArray中的后备存储长度完全无关紧要。可以把它改写成任何值但仍然不能读或写越界。
每个索引存储在数组的元素上。内存中值的表示形式由数组的“元素种类”决定,该数组由原始JSArray对象的映射决定。在本例中,这些值是小整数,是31位整数,底部位设置为0。1表示为1 << 1 = 2,2表示为2 << 1 = 4,以此类推。
元素类型是什么意思?
元素类型
V8中的数组也有一个元素类型的概念. 在这里找到所有元素类型的列表, 但是基本的思想是这样的: 在V8中,任何时候创建一个数组,它都被标记为一个elements kind,它定义了数组包含的元素的类型。三种最常见的元素类型如下:
- PACKED_SMI_ELEMENTS: 该数组是打包的(即没有洞),只包含Smis(31位小整数,第32位设为0)。
- PACKED_DOUBLE_ELEMENTS: 和上面的相同,但用于双精度(64位浮点值)。
- PACKED_ELEMENTS: 和上面一样,不同的是数组只包含引用。这意味着它可以包含任何类型的元素(整数、双精度浮点数、对象等)。
这些类型的元素还有一个有洞的变体(HOLEY_SMI_ELEMENTS,等等),它告诉引擎数组中可能有洞(例如,[1,2,,,4])。
数组也可以在元素类型之间进行转换,但是这种转换只能指向更一般的元素类型,而不能指向更具体的元素类型。例如,PACKED_SMI_ELEMENTS类型的数组可以转换为HOLEY_SMI_ELEMENTS类型的数组,但是转换不能以相反的方式发生(即填充已经有洞的数组中的所有洞不会导致转换到已填充的元素类型变体)。
这张图展示了最常见的元素类型的过渡(从这篇a V8 blog post建议读它来了解元素种类的更多信息):
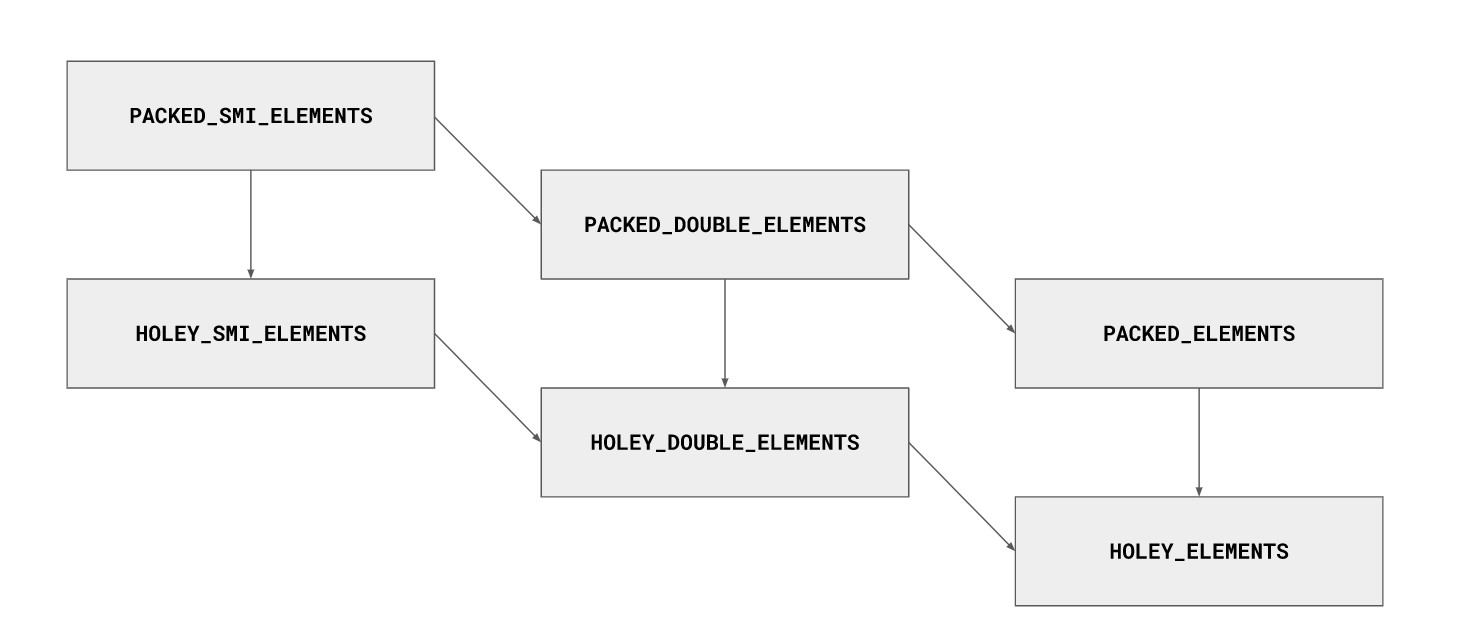
元素类过渡
在这篇博文中,只关心属于元素类型的两件事:
SMI_ELEMENTS和DOUBLE_ELEMENTS类数组将它们的元素存储在一个连续数组后备存储器中,作为它们在内存中的实际表示形式。例如,数组[1.1, 1.1, 1.1]将存储0x3ff199999999999a到内存中一个由三个元素组成的连续数组中(0x3ff199999999999a是1.1的IEEE-754表示)。另一方面,PACKED_ELEMENTS类型数组将存储三个对HeapNumber对象的连续引用,而HeapNumber对象又包含1.1的IEEE-754表示。还有一些基于字典的后备存储的元素种类,但这对本文来说并不重要。
因为SMI_ELEMENTS和DOUBLE_ELEMENTS类型数组的元素有不同的大小(Smis是31位整数,而double是64位浮点值),所以它们也有不同的kMaxLength值。
THE POCS
Sergey提供了两种证据的概念: 第一个给了一个数组长度的一种HOLEY_SMI_ELEMENTS FixedArray::kMaxLength + 3, 而第二个给了一个数组长度的一种 HOLEY_DOUBLE_ELEMENTS FixedDoubleArray::kMaxLength + 1。只是利用概念的第二个证明来构造最终的越界访问原语,稍后看看为什么这样做。
这两个概念的证明都使用了Array.prototype.concat最初获得一个数组,其大小刚好低于对应元素类型的kMaxLength值。一旦完成,Array.prototype.splice用于向数组中添加更多元素,这将导致其长度超过kMaxLength。这是因为Array.prototype.splice的快速路径间接利用新的Torque函数来分配新的数组,如果原来的数组不够大。好奇的人可能会发现,实现这一目的的函数调用链如下:
1 | // builtins/array-splice.tq |
可能想知道为什么不能创建一个大小刚好低于FixedArray::kMaxLength的大数组并使用它。试试(使用优化的release版本,除非想等待很长时间):
1 | $ ./d8 |
这不仅需要一些时间来运行,还会得到一个OOM(内存不足)错误!发生这种情况的原因是数组的分配不是一次性完成的。对AllocateRawFixedArray有大量调用,每个调用都分配一个稍大一些的数组。在GDB中,可以通过在AllocateRawFixedArray设置断点,然后像上面所示的那样分配数组来看到这一点。不完全确定V8为什么这样做,但是这么多的分配会导致V8很快耗尽内存。
另一个想法是使用FixedDoubleArray::kMaxLength代替,因为它明显更小(再次使用优化的release版本):
1 | // FixedDoubleArray::kMaxLength = 0x3fffffe |
这确实有效,它返回一个新的HOLEY_DOUBLE_ELEMENTS类型数组,其长度设置为FixedDoubleArray::kMaxLength + 1,因此可以使用它来代替array.prototype.concat。相信这个工作的原因是,分配大小为0x3fffffd的数组所需的分配数量足够小,不会导致引擎走向OOM。
不过,这种方法有两个很大的缺点: 分配和填充这么大的数组需要相当多的时间(至少在我的机器上是这样),因此它在利用上不太理想。另一个问题是,在内存受限的环境(如旧手机)中以这种方式触发漏洞可能会导致引擎崩溃.
另一方面,Sergey的第一个poc在我的机器上只花了2秒,而且内存效率很高,所以分析一下.
第一个poc
第一个poc如下。确保使用优化的release版本来运行它,否则它将需要非常长的时间才能完成:
1 | array = Array(0x80000).fill(1); // [1] |
一步一步来分析.
在[1]上,创建一个大小为0x80000的数组,并用1填充。这种大小的数组需要大量的分配,但这并不能让引擎变得强大。因为数组最初是空的,所以它获得一个HOLEY_SMI_ELEMENTS类型,并且在它被1填充之后仍然保留该元素类型.
稍后会回到[2],但是在[3],一个新的args数组是用0xff元素创建的。每个元素都被设置为在[1]处创建的数组。这给args数组提供了总共0xff * 0x80000 = 0x7f80000个元素。在[4]处,另一个大小为0x7fffc的数组被推入args数组,这将使它的元素总数为0x7f80000 + 0x7fffc = 0x7fffffc。0x7fffffc仅仅比FixedDoubleArray::kMaxLength = 0x7fffffd少一个.
在[5]处, Array.prototype.concat.apply将args数组中的每个元素连接到空数组[]. You can read more about how Function.prototype.apply() works here, 但它实际上将args视为参数数组,并将每个元素连接到最终结果数组。我们知道元素的总数是0x7fffffc,所以最终的数组会有这么多元素。这种连接进行得有点快(在我的机器上大约需要2秒),尽管它比前面展示的简单创建数组要快得多.
最后, 在[6], Array.prototype.splice向数组添加4个额外元素,这意味着它的长度现在是0x8000000,即FixedArray::kMaxLength + 3.
唯一需要解释的是[2],其中一个属性被添加到原始数组中。要理解这一点,必须首先理解,对于几乎所有的V8内置函数来说,一个约定是有一个快的路径和一个慢的路径。在Array.prototype.concat的情况下,一种采用慢路径的简单方法是向正在连接的数组添加属性(实际上,这是大多数Array.prototype采用慢路径的一种简单方法。*内置函数)。为什么Sergey想要走慢路? 因为快速路径有以下代码:
1 | // builtins/builtins-array.cc:1414 |
如所见,快速路径检查以确保最终数组的长度不超过任何一个kMaxLength值。因为FixedDoubleArray::kMaxLength是FixedArray::kMaxLength的一半,上面的poc永远不会通过这个检查。可以尝试在不使用数组的情况下运行代码array.prop = 1;看看会发生什么!
另一方面,慢路径(Slow_ArrayConcat)没有任何长度检查(但如果长度超过FixedArray::kMaxLength,它仍然会崩溃,因为它调用的其中一个函数仍然会检查这个长度)。这就是为什么Sergey的poc使用了慢路径: 绕过存在于快速路径上的检查.
第二个poc-第一部分
尽管第一个poc证明了该漏洞并可用于利用(只需稍微修改第二个poc中的触发器函数),但需要几秒钟才能完成(在优化的release版本上),这可能不是理想的。Sergey选择使用一个HOLEY_DOUBLE_ELEMENTS类型数组来代替。这可能是因为FixedDoubleArray::kMaxLength值明显小于它的FixedArray变量,导致更快的触发(在未优化的构建上几乎是即时的)。如果理解了第一个poc,那么下面关于第二个poc的第一部分的注释应该是不言自明的:
1 | // HOLEY_DOUBLE_ELEMENTS类型,size=0x40000,填充1.1 |
一旦到了这一点,giant_array的长度是0x3ffffff,这是FixedDoubleArray::kMaxLength + 1。现在的问题是,如何利用这个数组?没有立即得到任何有用的原语,因此需要找到引擎的其他部分,其代码依赖于数组长度永远不能超过kMaxLength值这一事实.
对于大多数研究人员来说,这个bug本身是很容易发现的,因为只需要比较函数的新Torque实现和旧的。但是,要知道如何利用它,需要对V8本身有更深入的了解。Sergey采用的开发途径是使用V8的投机性优化编译器TurboFan,这需要自己的介绍.
TURBOFAN
请注意,TurboFan是V8发动机的一个极其复杂的组成部分。可以很容易地用几个小时来讨论它的内部结构,因此本节不会是一个详尽的介绍。
如果已经知道TurboFan是如何工作的,可以跳过这一节。
历史
和现在大多数大型JavaScript引擎一样,V8一开始只是一个JavaScript的解释器。随着计算机变得越来越强大,人们想要开始在浏览器中运行越来越复杂的应用程序,面对现实吧,基于浏览器的应用程序更容易移植。尽管只有一个解释器,V8很快就达到了性能限制.
当达到这个极限时,V8开发人员就制造了TurboFan(好吧,也不完全是。他们首先构建了Crankshaft,但不讨论它),这是一个投机性优化编译器,它使用解释器的类型反馈将JavaScript代码编译为本地机器代码。下图大致展示了V8当前的工作方式(从这篇博客上摘取):
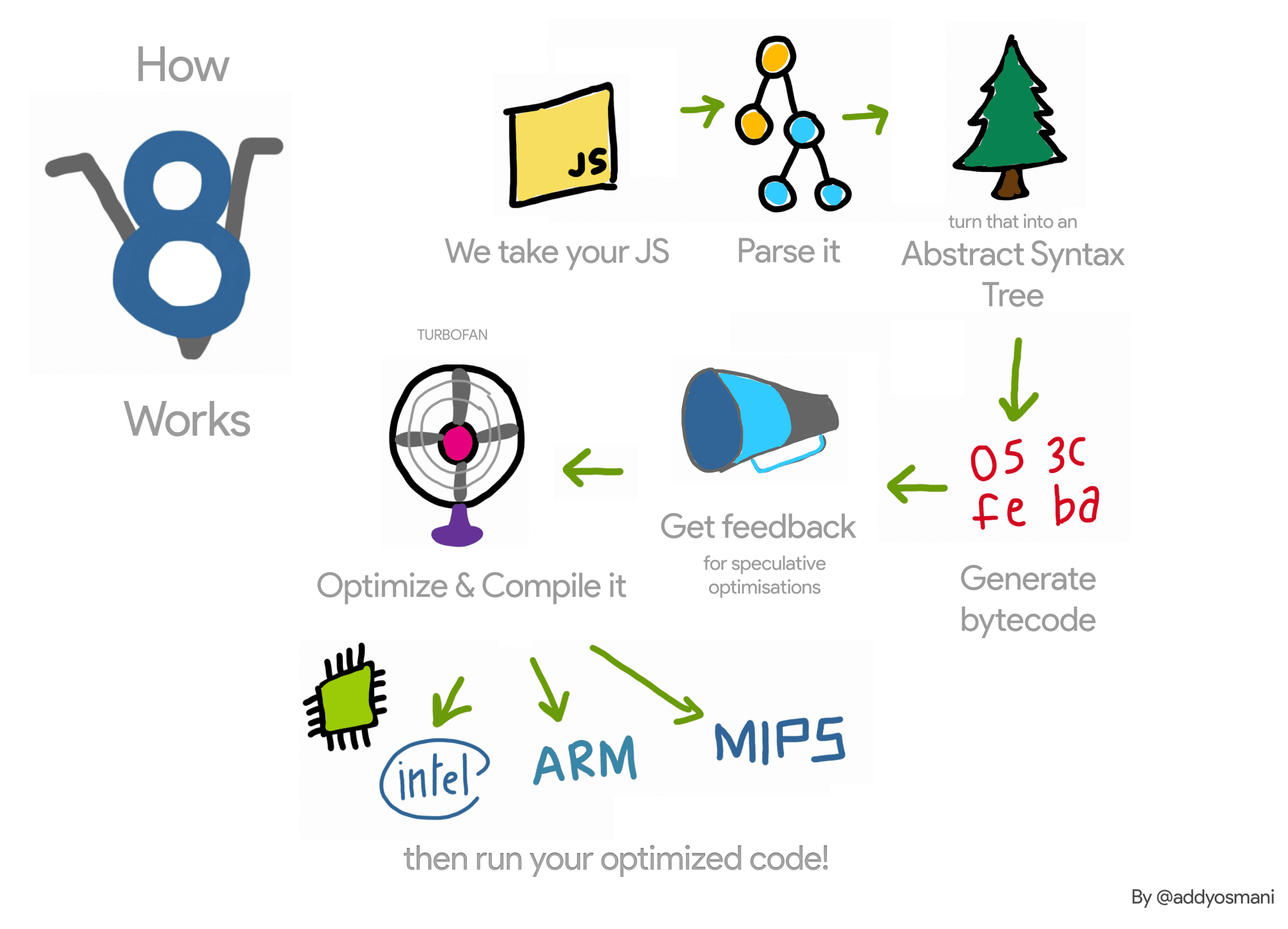
V8管道执行
投机优化
TurboFan在一个函数一个函数的基础上编译JavaScript代码。在JavaScript中,函数最初几次被调用时,解释器会执行它,解释器会收集类型反馈。在此上下文中,类型反馈只是指传递到函数中/在函数中使用的类型的信息。这种类型的反馈随后被TurboFan用于 “推测性” 优化,这基本上意味着TurboFan将使用这种类型的反馈进行假设,从而生成本地代码。
来看一个例子。假设有以下代码:
1 | function add(val1, val2) { |
当在循环中调用add(5,10) 10000次时,解释器收集类型反馈,TurboFan将使用这些反馈进行假设并生成本机汇编代码,将val1和val2简单地添加在一起,就像它们是Smis一样。
本机程序集代码运行得非常快,但这里有一个问题。JavaScript是一种动态类型语言,所以没有什么可以阻止向add函数传递字符串或对象。TurboFan需要防止这种情况,因为将两个字符串相加与将两个数字相加是完全不同的,所以在两种情况下运行相同的本地代码会导致bug。为了防止这种情况发生,在本地代码中插入了类型保护,以检查val1和val2都是Smi类型。只有在类型检查通过时才执行本机代码。如果任何一个检查失败,那么代码将被反优化,并将执行“保释”给解释器,解释器可以处理所有情况。
用V8的–trace-opt和–trace-deopt flag运行上面的代码,看看优化和反优化是如何进行的:
1 | $ ./d8 --trace-opt --trace-deopt test.js |
可以看到,由于 “调用的类型反馈不足” ,函数得到了优化,后来又被取消优化,这是有意义的! 从未使用字符串调用函数,因此没有要引用的类型反馈,因此出现了反优化。
优化阶段
TurboFan不仅仅是一个推测编译器。它也是一个优化编译器,这意味着它有许多不同的优化阶段。下图显示了一个粗略的管道(taken from this blog post):
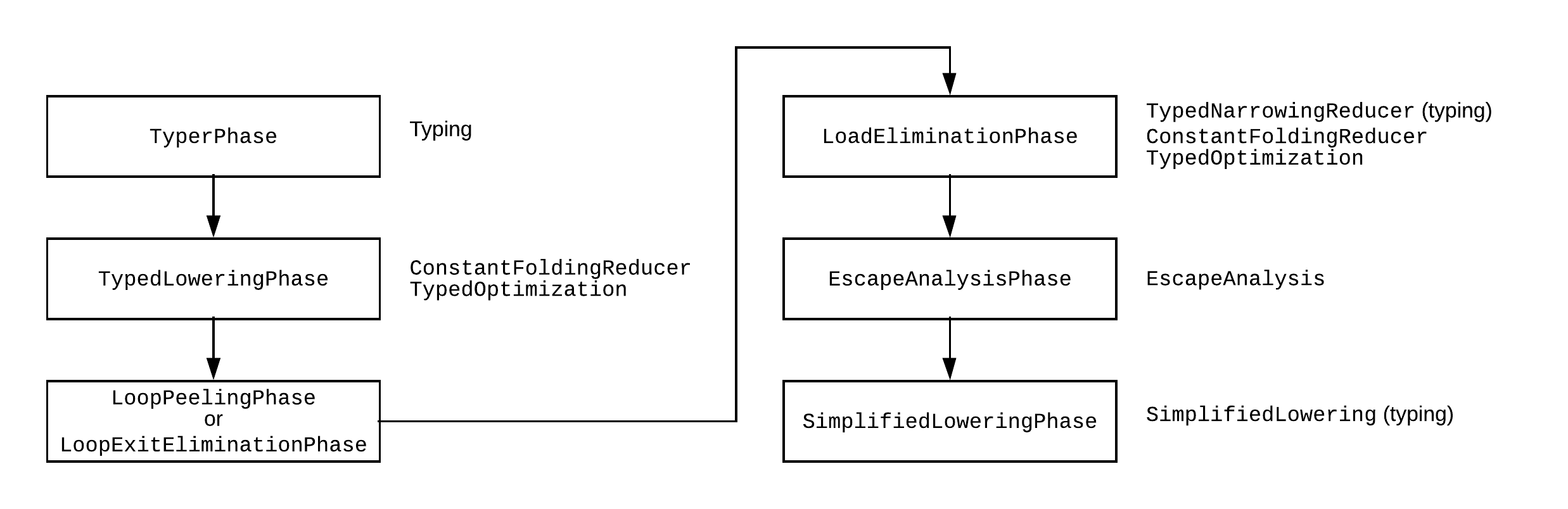
TurboFan优化阶段(注: 不是详尽的图)
如果上过编译器课程(或以前学过编译器),那么这些术语对您来说可能很熟悉。它们只是TurboFan在某些优化阶段执行的编译器优化。但是,在解析器生成的AST上进行这些优化非常困难,因此TurboFan将AST转换为另一种表示形式: “节点的海洋” 图。
节点的海洋
TurboFan在源代码的大量节点表示上进行优化。提供它如何工作的简要总结,可以参考这两者这篇博文和这篇博文如果想更好地理解它的话.
节点海图中的节点可以表示高级操作,也可以表示低级操作。节点本身与边相连,边有三种类型.
值边用于将值传递给可能使用它们的节点。在下面的示例中,值1和5将使用值边传递给加法节点
1 | +---------+ +---------+ |
控制边用于定义控制流。例如:
1 | +---------+ +---------+ |
最后,效果边用于显示改变程序状态的操作顺序。这些边由虚线定义(其他两种边用实线绘制)。理解效果边的一种方法是考虑这样一种场景: 加载对象的属性,修改它,然后将其存储回对象中。在一个节点海图中,负载节点将有一条效果输出边进入修改节点,而修改节点将有一条效果输出边进入存储节点。这样,引擎就知道操作的顺序是load -> modify -> store.
下面的图片来自这篇博文,展示了边缘效果:
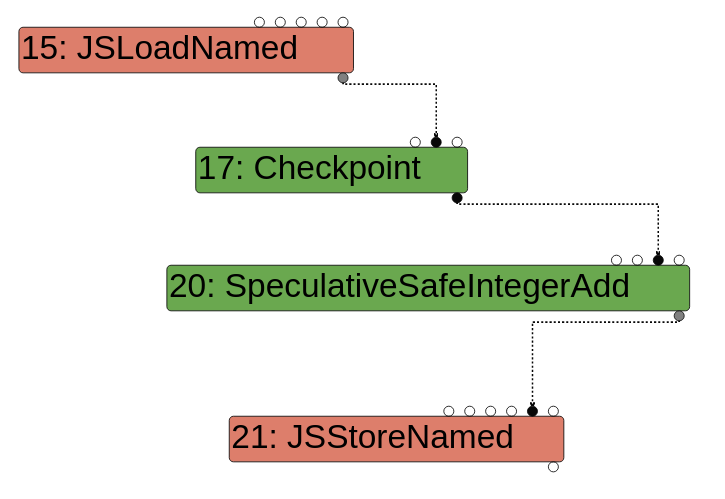
Turbolizer边缘效应
来看看前面所展示的add函数的节点海表示。为此,使用Turbolizer,这是V8开发者创建的一个工具,用来查看各个优化阶段的TurboFan节点海图。
在v8的根目录下设置Turbolizer(确保首先安装最新版本的npm和nodejs):
1 | $ cd tools/turbolizer |
一旦这一步完成,访问 https://localhost:1337 在Chrome或Chromium(必须是这些浏览器之一),会看到以下输出:
Turbolizer主屏幕
Turbolizer的工作方式是通过使用–trace-turbo选项运行V8来生成.json文件。例如,可以运行add函数的代码如下:
1 | // test.js |
1 | ~/projects/v8/v8/out/x64.release$ ./d8 --trace-turbo test.js |
turbo-*。看到的json文件是需要上传到Turbolizer。点击Turbolizer右上方的按钮,上传文件,应该看到:
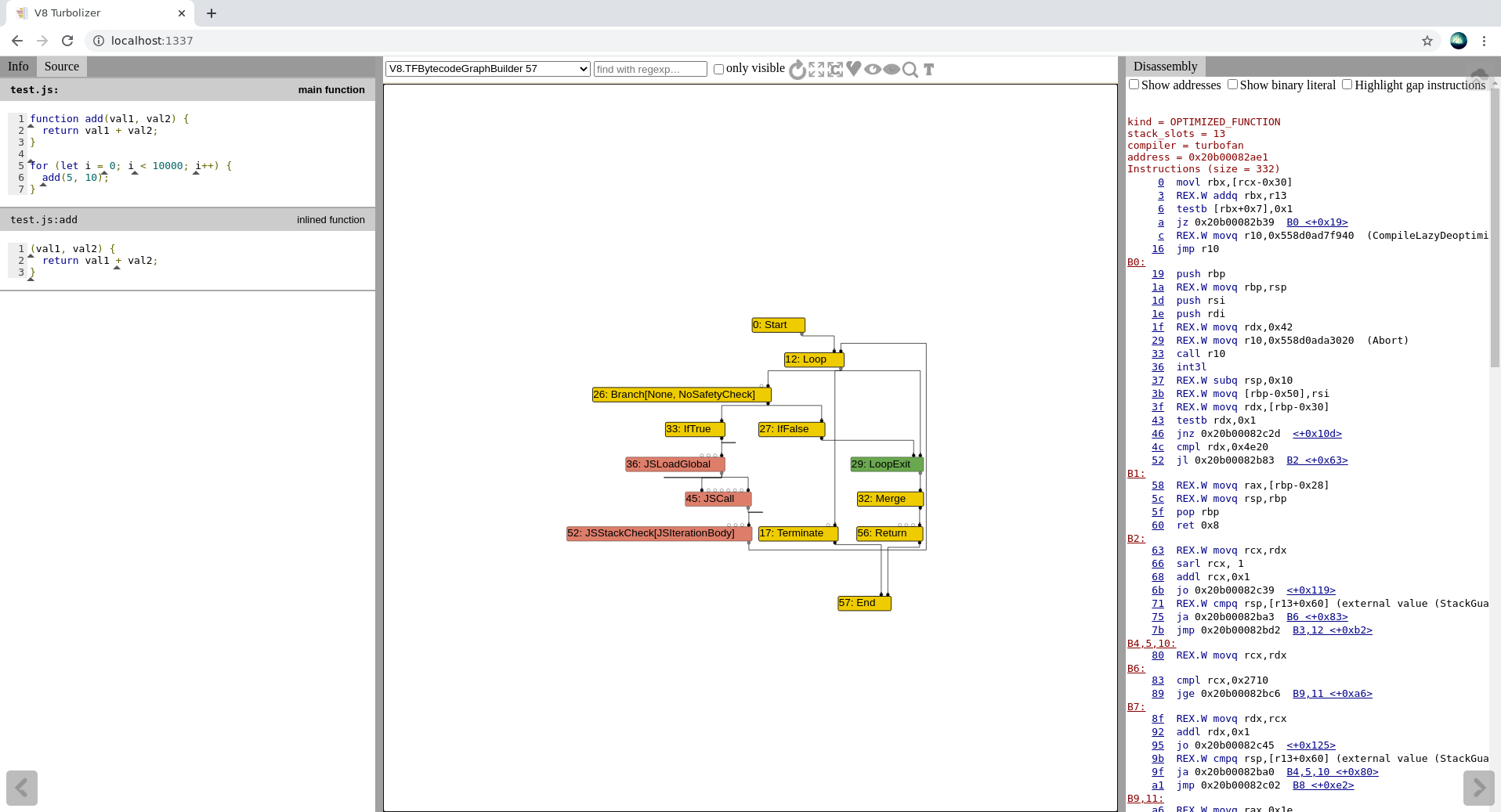
Turbolizer添加功能 - 图形构建阶段
在左边,可以看到实际的源代码,而在右边,可以看到生成的机器码。在中间,有海节点图,目前有很多节点隐藏(这是默认行为).
将在类型阶段查看所有节点,因为想了解TurboFan是如何对函数进行类型输入的。从顶部的下拉菜单中,选择V8.TFTyper选项。接下来,点击“显示所有节点”按钮,然后点击“布局图”按钮,最后点击“切换类型”按钮。这将显示每个节点,整齐地显示图表,并显示TurboFan推测的类型.
当前的图形有太多的节点,无法在一个截图中查看,所以将有选择地隐藏不重要的节点。如果想知道如何知道哪些节点是重要的,哪些节点不是,这只是基于之前使用Turbolizer的知识。建议尝试不同的测试代码,看看Turbolizer是如何布置节点海图的,以便了解更多. 之前提到的博客文章也要看一些例子.
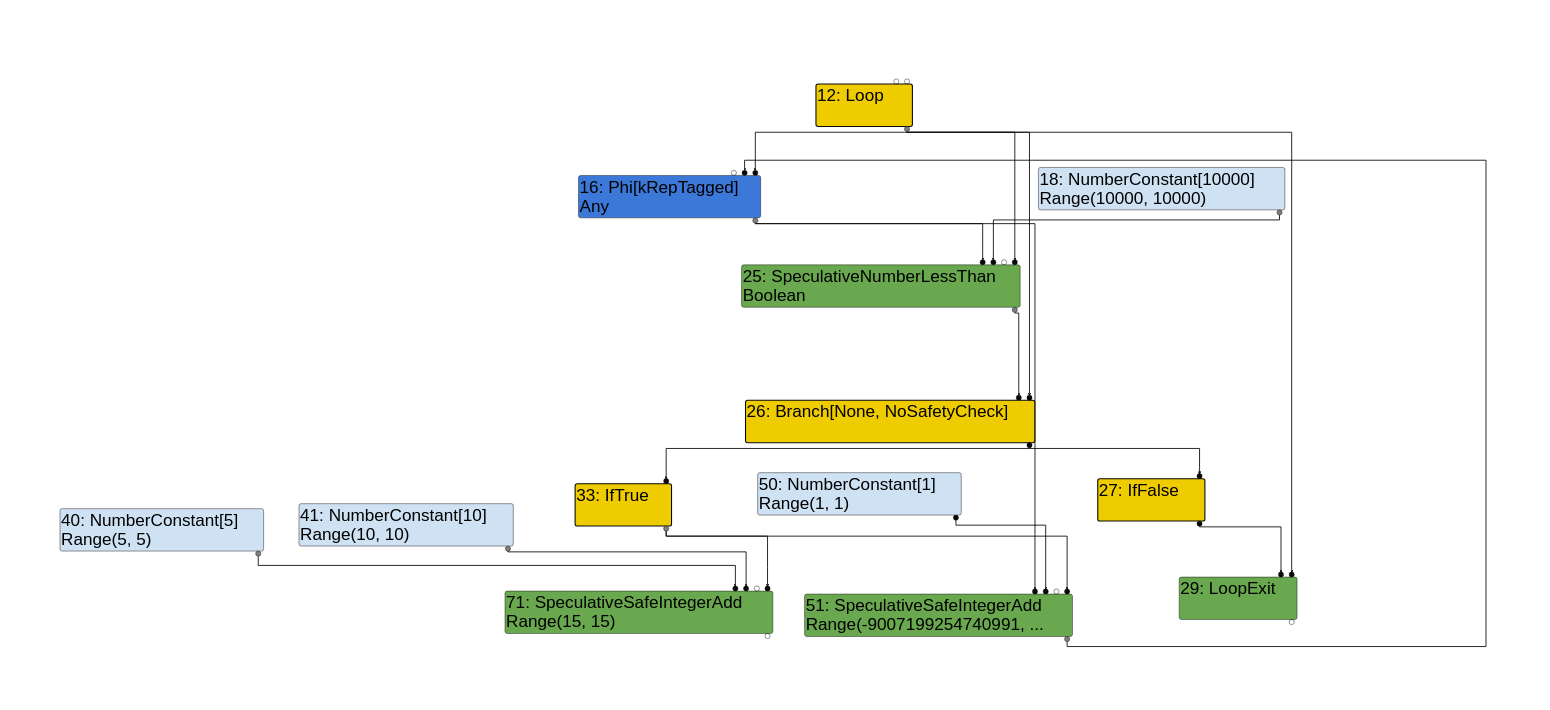
Turbolizer添加函数型相位
- 会注意到以下几点:
一开始,有一个循环节点,它表示将要进入一个循环。从这里出来的、进入Branch和LoopExit节点的边是控制边。
使用Any类型的Phi节点和使用Range(10000, 10000)类型的NumberConstant[10000]节点将被传递给使用Boolean类型的SpeculativeNumberLessThan节点。节点是循环变量,它将与这里的NumberConstant[10000]进行比较,看它是否小于10000。这里的边是值边。
SpeculativeNumberLessThan节点引出一个分支节点,该分支节点又引出一个IfTrue或IfFalse节点。如果到达了IfFalse节点(即loop变量不小于10000),那么只需执行一个LoopExit。
在IfTrue分支中,会发生两件事。首先,使用SpeculativeSafeIntegerAdd将两个常量5和10相加,该常量已正确键入范围(15,15)。其次,看到循环变量被添加了一个常量1。用于此添加的SpeculativeSafeIntegerAdd节点的类型是一个范围(-9007199254740991,9007199254740991)。这样做是因为loop变量的初始类型是Any,这意味着TurboFan需要处理所有可能的情况,其中Any类型可以添加到常量1。这刚好是一个很大的范围。
分支之间的边,IfTrue和IfFalse边都是控制边。
TurboFan类型编号有一个范围(最小,最大)。如果它们被推测为只有一个可能的值,那么最小值和最大值是相等的,否则它们就不相等(如循环变量的情况)。
TurboFan也做了另一个优化。它友好地将add函数内联到循环中(注意没有jcall指令,这是节点海图调用函数的方式)。
结果值返回省略了出口的情况,但可以在自己的TurboFan图上看,如果好奇的话。图中也没有显示效果边,但这是因为这里没有真正改变程序中任何变量/对象的状态的操作。
本节的主要内容如下:
了解如何使用TurboFan来查看优化代码的节点图海。
对节点不同类型边的理解。
了解节点的类型。这对于下一节的第二个poc的解释尤其重要。
对TurboFan控制流工作原理的粗略了解。注意,当说到控制流时,并不是指分支节点,而是指如何确定节点执行的顺序。使用 “布局图” 选项将使TurboFan大致顺序的图形化,这样可以阅读它自顶向下的方法。它通过跟踪每个节点的效果输出边来了解顺序,但这并不总是100%准确的,所以需要一边做一边弄清楚。当然,将根据需要在这篇文章中解释一切,所以不必担心没有完全理解这一点。
重新访问第二个POC
记住以上所有信息后,现在就可以完成第二个poc的其余部分了。
欺骗TYPER
第二个poc的其余部分如下所示:
1 | //在这个'splice'调用之后,调用giant_array.Length = 0x3ffffff = 67108863 |
在V8中,length_of_double的定义方法只是将实际浮点值存储到变量中的一种方法。记住,JavaScript只有数字和大整数的概念。Sergey在这里做的是将大整数0x2424242400000000存储到BigUint64Array中,然后使用与BigUint64Array相同的缓冲区(后台存储)创建一个新的Float64Array。然后,只需通过float数组访问0x2424242400000000值,并将其存储在length_as_double中。稍后将看到如何使用它.
从查看触发器函数的第一部分开始,看看它是如何工作的。从节点海图开始,特别是在类型阶段。执行./d8—trace-turbo poc.js,在Turbolizer中打开新生成的turbo-trigger-0.json,并切换到Typer阶段。首先,将只显示为该函数创建的节点,直到看到标有[1]的行:
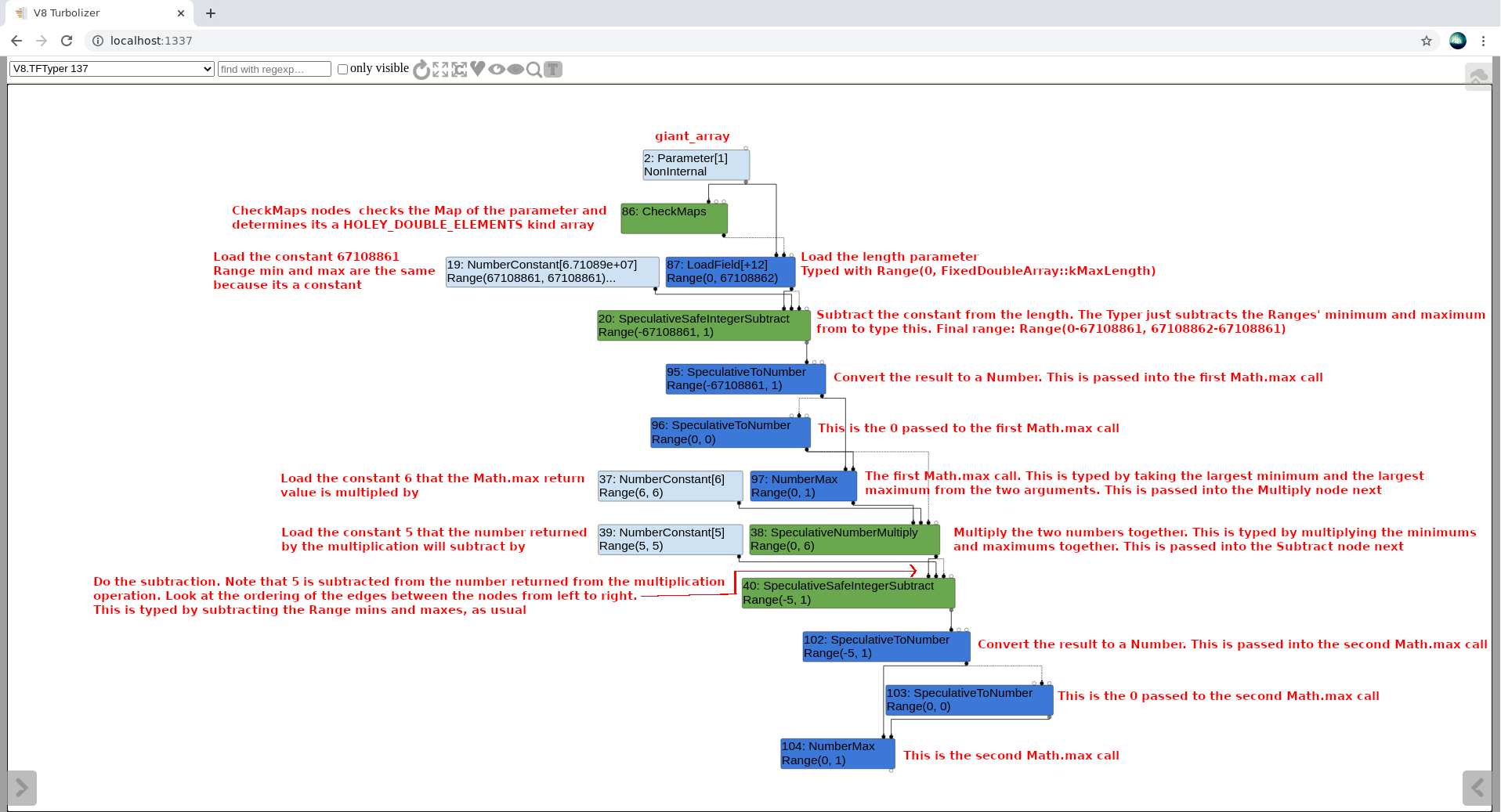
Turbolizer触发功能类型1(在移动设备上,在新选项卡中打开图像)
通读图像,查看类型如何对所有节点进行type,直到第二次Math.max的call。注意到,输入器正确地执行了所有操作,但是这里还有一个大问题没有解决。
类型假设传入的数组的length字段的类型为Range(0, 67108862)。这在图顶部的LoadField[+12]节点中显示。它从下面的代码中获取:
1 | // src/compiler/type-cache.h:95 |
这里的问题是,传入的数组(giant_array)的长度实际上是67108863! 如果把它记在脑子里,会得到一个完全不同的图像。下面是一个poc的注释版本,通过显示类型的想法和类型实际是什么来演示这个问题:
1 | function trigger(array) { |
如所见,末尾的类型决定了x只能在range(0,1)的范围内,但根据实际传入的数组,知道范围实际上应该是range(0,7),因为x = 7! 所以实际上骗过了typer。现在的问题是,如何利用它?
糊弄TYPER == 写越界
触发器函数的下一部分如下所示:
1 | length_as_double = |
看看这部分函数的turbolizer图(这比之前的少一点啰嗦):
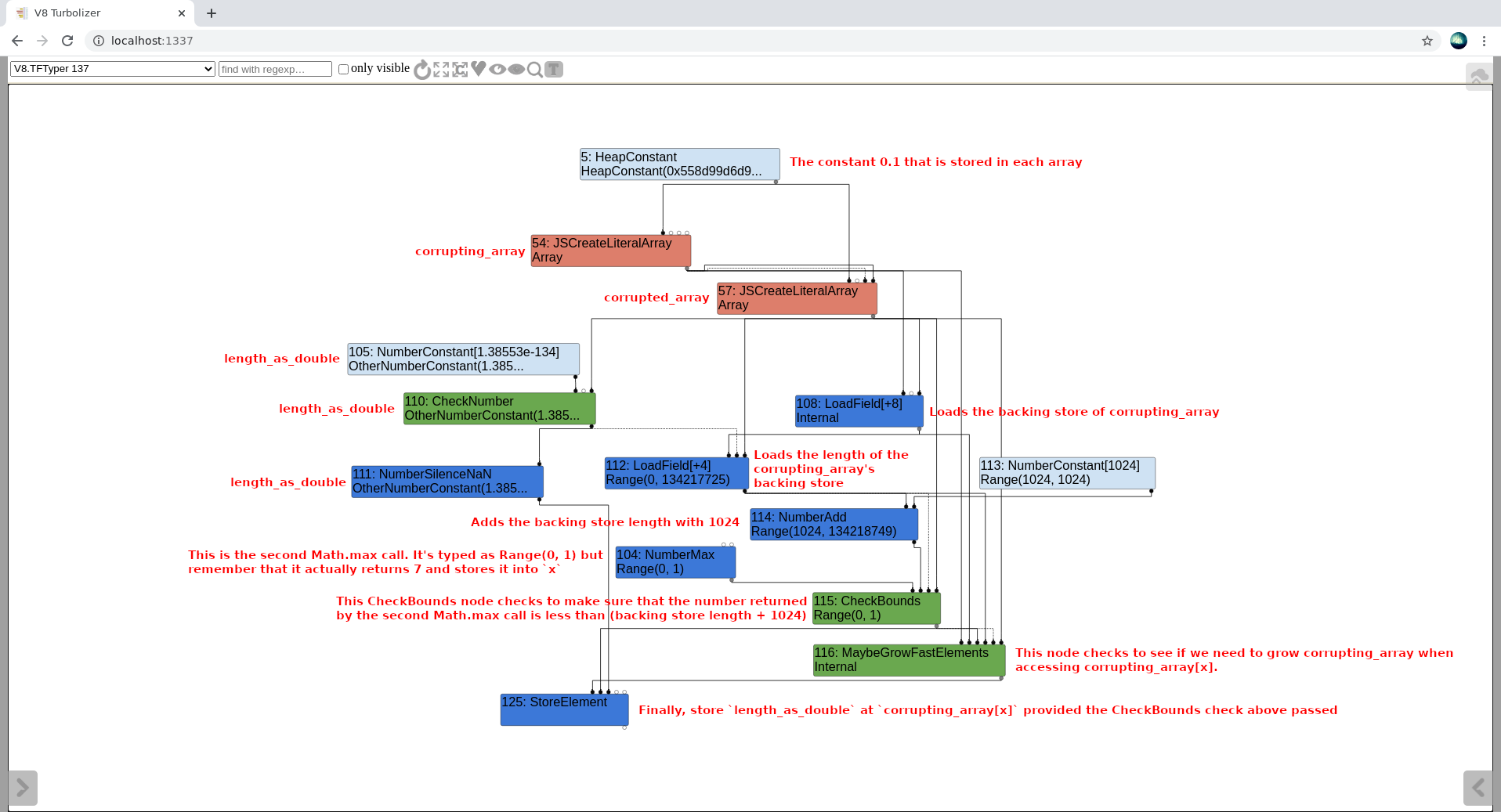
turbolizer触发功能类型2(在移动设备上,在一个新标签打开图像)
这张图有点难读,因为它有点杂乱无章,但希望它能把要点讲清楚。主要结论如下:
这里的CheckBounds节点很有趣,因为它在进行边界检查。在本例中,范围(0,1)继承自NumberMax节点的类型。CheckBounds节点本质上取输入边0的值,并确保它小于输入边1的值。在此上下文中,“输入边”是指从节点上方进入该节点的边。输入边0是最左边的边,输入边1是第二左边的边,以此类推.
在本例中,输入边0是第二个 x = Math。调用max(x, 1),返回值7(请记住此处的类型不正确)。这里的CheckBounds节点确保x在范围的范围内(1024,FixedArray::kMaxLength+1024)。这样做的原因是,向大于length + 1024的索引写入需要引擎将corrupting_array的备份存储转换为字典,这将要求对该函数进行反优化.
关于CheckBounds节点需要注意的另一件重要事情是,它们的功能与specativenumberlessthan节点稍有不同。使用SpeculativeNumberLessThan节点,TurboFan会将推测的索引类型(Range(0,1))与限制类型进行比较。然而,对于CheckBounds节点,只要TurboFan到达该节点,它就会获取索引节点的实际值(在本例中是x),并将其与限制类型进行比较。这意味着导致输入者错误地将x作为范围(0,1)输入的事实没有意义。仍然需要确保它的实际值小于或等于length + 1024,否则函数将反优化。这很好,因为在poc代码中x等于7,但要记住的一点很重要,因为可以让x等于任何值,并且仍然可以使用原始bug将其输入为范围(0,1).
一旦通过了CheckBounds节点,就可以进入MaybeGrowFastElements节点。这个节点是检查corrupting_array之前访问索引x。一旦通过这个节点,终于有一个StoreElement节点存储length_as_double (0 x2424242400000000)的浮点表示成corrupting_array [x].
有一个未知因素在起作用。这个MaybeGrowFastElements节点是什么,它是如何工作的? 不希望它在访问下标x之前增长corrupting_array,因为这样它就不会再访问越界了.
为了了解这个可能是growfastelements节点是如何工作的,需要看一下TurboFan的负载消除优化阶段。在这个阶段,如果TurboFan遇到了一个MaybeGrowFastElements节点,它最终会通过调用TypedOptimization::ReduceMaybeGrowFastElements函数来优化它:
1 | // compiler/typed-optimization.cc:166 |
看看之前的turbolizer图,注意到输入边2的值是从之前的CheckBounds节点进来的实边。这条边将包含typer从最终计算中确定的Math.max(x, 1)调用,它是Range(0,1)。它被存储在[1]的index变量中.
另一方面,Value input edge 3是LoadField节点,它加载[2]上的corrupting_array后备存储的长度。在图中,它的类型是Range(0,134217725)(与Range(0, FixedArray::kMaxLength)相同),但是后来通过LoadElimination::ReduceLoadField优化为NumberConstant类型的Range(2,2)。类型可以这样做,因为它知道corrupting_array的长度是2.
LoadField节点优化最终适合, 因为一旦得到在[3]if语句, index_type.Max()返回1(范围(0,1)), 而length_type.Min()返回2(范围(2,2)), 这意味着index_type.Max () < length_type.Min()返回true, 和执行进入if语句.
执行进入if语句的事实告诉TurboFan以下信息: 几乎可以肯定,根据代码的编写方式,被访问的数组(在本例中是corrupting_array)永远不需要增长。面对这个问题,如果索引所能得到的最大值总是小于长度所能得到的最小值,为什么还要增加数组的容量呢?
TurboFan现在可以使用这个假设来修改节点海图,那么它会做什么呢? 它试图优化MaybeGrowFastElements节点,但在这方面非常小心。它知道,作为一个投机性优化编译器,它所做的假设可能是不正确的。它通过创建一个新的CheckBounds节点来防止类似这样的错误假设.
在if语句中,看到在[4]处创建这个CheckBounds节点。有几个参数传递给这个新节点,但只关心这里的index和length参数。基于CheckBounds节点是如何工作的,我们知道,当达到这个新创建的CheckBounds节点时,TurboFan将检查以确保索引的实际价值(在这种情况下,x == 7)小于或等于长度的值(在本例中,一个NumberConstant范围(2,2))。显然,7不小于或等于2,所以执行会返回到解释器,所有的希望都失去了…… 除非因为这个函数的错误CheckBounds节点从未被插入到节点海图.
这个函数确实有一个错误。Sergey在bug追踪器中简单地说了一下,所以更深入地看看它。错误在直线上标有[5],ReplaceWithValue叫做与两个参数,当前节点(即MaybeGrowFastElements节点),元素节点,输出值之间的固体边缘LoadField(+8)节点和MaybeGrowFastElements节点。这是corrupting_array的后备存储.
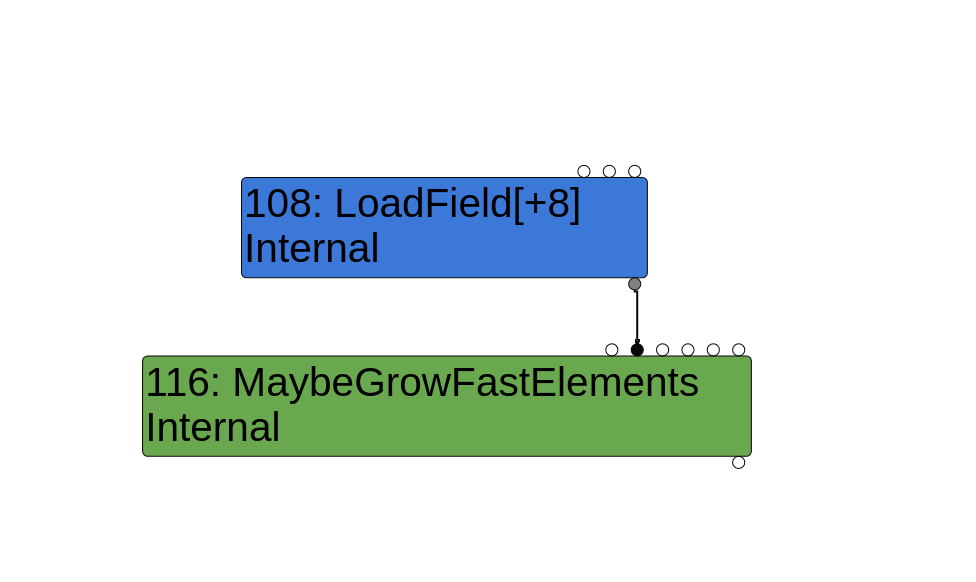
LoadField和MaybeGrowFastElements之间的值边缘
这里的问题是,ReplaceWithValue实际上有四个参数:
1 | void GraphReducer::ReplaceWithValue(Node* node, Node* value, Node* effect, |
实际应该发生的是调用ReplaceWithValue(node, elements, check_bounds),并将check_bounds作为node* effect参数传入。由于从未传入check_bounds, Node* effect参数最终成为nullptr,这导致它成为[1]处传入的效果输入节点(在本例中是与length + 1024相比的另一个CheckBounds节点)。请记住,节点海图上的效果边是虚线,而值边和控制边是实线。MaybeGrowFastElements节点周围的边缘如下所示:
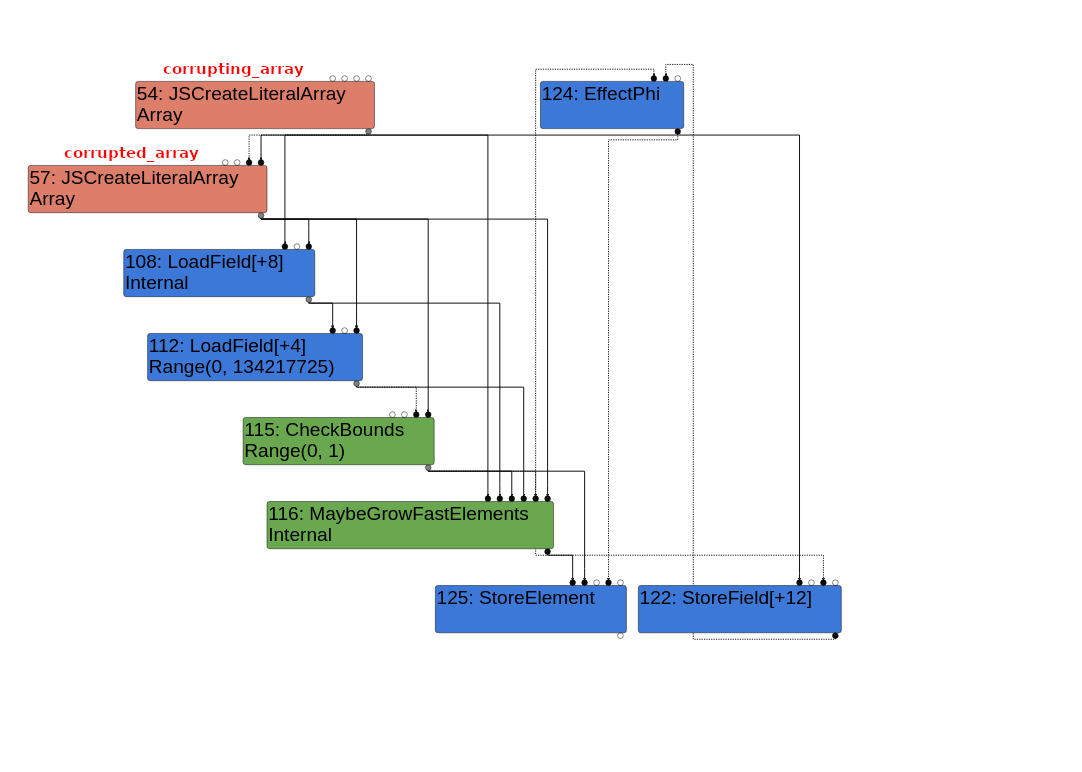
MaybeGrowFastElements边缘
[2]处的for循环遍历MaybeGrowFastElements节点的每条输出边,并作为参数传入的相应节点替换该边的 “输入节点”。例如,传入的Node* value参数是LoadField[+8] 节点 (value input edge 1),它加载corrupting_array的元素指针。MaybeGrowFastElements的唯一输出值边是通向StoreElement节点的边,因此当for循环遍历该值边时,图本质上转换为
1 | value value |
到
1 | LoadField[+8] <--- StoreElement |
真正的错误发生在[3]。这里的边缘变量是MaybeGrowFastElements节点与StoreField[+12]和EffectPhi节点之间的效果输出边缘。希望这条边的输入节点(目前MaybeGrowFastElements节点)替换为创建的新的CheckBounds节点,因为,当这一切发生的时候,新的CheckBounds节点会影响输出本身之间的边缘和StoreField(+12)和EffectPhi节点.
为什么拥有这种效果输出边如此重要? 如果新的CheckBounds节点有一条到另一个节点的输出效果边,它就告诉TurboFan,在这个新的CheckBounds节点完成它的工作之前,其他节点不能做需要它做的任何事情。它告诉TurboFan这个CheckBounds节点很重要。请记住,效应边是TurboFan确定需要执行特定顺序的节点.
现在,Node* effect参数被设置为链接到MaybeGrowFastElements节点的前一个CheckBounds节点,而不是新创建的CheckBounds节点。这意味着StoreField[+12]和EffectPhi节点最终将它们到MaybeGrowFastElements节点的效果边替换为前一个Checkbounds节点的效果边.
由于新的CheckBounds节点没有影响任何输出边,TurboFan最终认为这是一个无用的CheckBounds节点(如果节点的实际输出对其他节点没有影响,为什么要检查边界呢?).
一旦ReplaceWithValue返回,Replace(check_bounds)调用将用新的CheckBounds节点替换MaybeGrowFastElements节点。由于新的CheckBounds节点没有输出边效果,被消除了,如下所示:
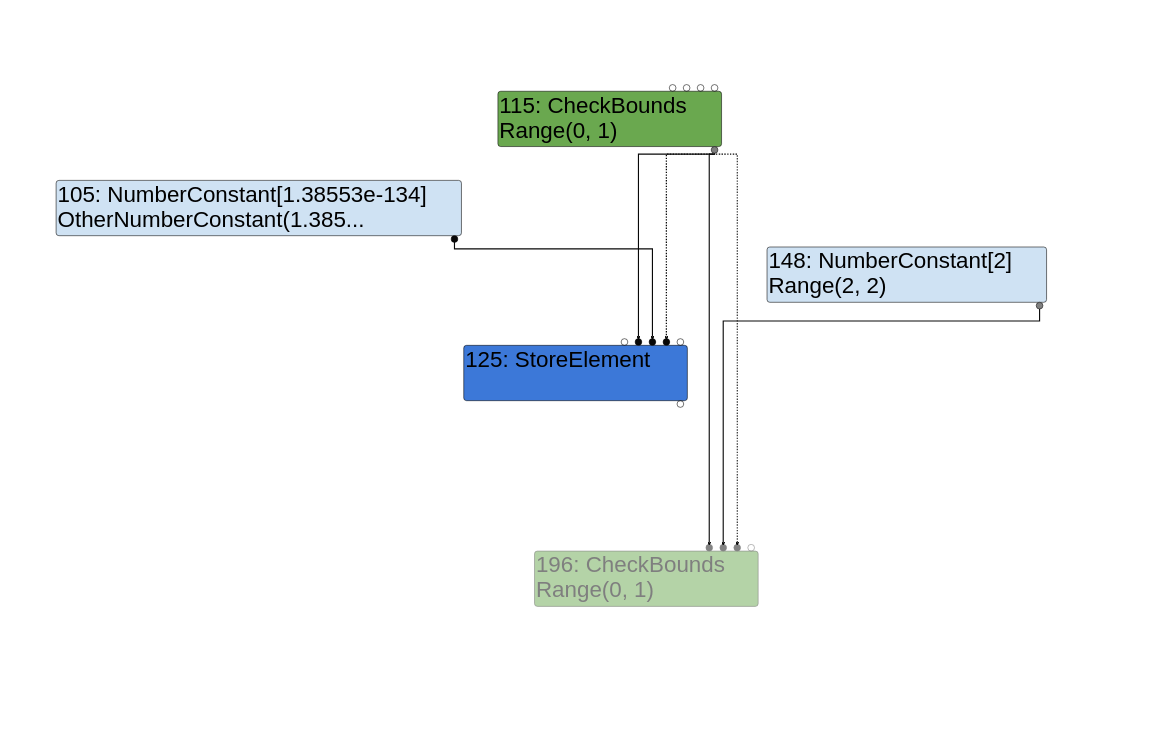
消除MaybeGrowFastElements
有鬼影效果的CheckBounds节点是新的CheckBounds节点,由于没有任何效果输出边被消除。可以看到它将其他CheckBounds节点的索引与常数2(这是corrupting_array的长度)进行比较,但没有其他节点使用它,因此它被认为是冗余的,因此被删除.
与连接到StoreElement节点的另一个CheckBounds节点进行检查,以确保x小于length + 1024。很高兴访问corrupting_array[x]越界,因为x = 7肯定小于length + 1024。数组不会增长,因为MaybeGrowFastElements节点已经被删除,并且引擎不会抱怨x = 7比corrupting_array.length = 2大,因为应该测试的这个CheckBounds节点已经被消除了!达到超出界限的写入!
越界写…但是在哪里?
已经达到了一个特定索引的边界(在这个例子中,x = 7)。Sergey选择7一定是有原因的。corrupted_array是在corrupted_array之前定义的,并且由于V8堆的确定性,corrupted_array将总是放在corrupted_array之后。由于在末尾以已损坏的长度返回了corrupted_array,因此对索引7的越界写入覆盖了corrupted_array的length属性是有意义的。可以在GDB中使用./d8 –allow-native-syntax运行以下代码来看到这一点:
1 | length_as_double = |
在GDB中运行它,在命中断点后向上滚动,复制corrupted_array的地址并查看它之前的几个四字节:
1 | $ gdb ./d8 |
注意,从地址中减去了1,因为在V8中指针的最后一位总是设置为1。
这里有几点需要注意:
V8堆中的所有指针都是32位的,但是每个数组中的0.1用64位的IEEE-754十六进制表示为0x3fb999999999999a。这是同时使用 x/wx 和 x/gx 查看堆部分的原因: 获得更清晰的堆图.
如果跟踪corrupted_array的下标超出其后备存储的边界,将注意到corrupted_array的元素指针是索引7的底部32位,而length属性是索引7的上部32位,索引7的特定值是0x178308792cfc的0x2424242400000000值.
因为corrupting_array是一个HOLEY_DOUBLE_ELEMENTS类型的数组,所以任何越界的写操作都会将64位的值写入选定的索引。Sergey将length_as_double设置为浮点表示0x2424242400000000。设置这个大值的原因是想覆盖length属性,让它恰好是这个索引的上32位.
这里的一个大问题是,当覆盖length属性时,必须同时覆盖elements指针。如果注意的话,会注意到%DebugPrint实际上在试图打印关于corrupted_array的信息时导致了一个分段错误。它这样做的原因是元素指针已经被重写为NULL,所以对它进行解引用时发生%DebugPrint段错误.
可能想知道,引擎如何知道后备存储的位置?现在访问任何corrupted_array的索引都会导致segfault,因为它会尝试访问元素指针?这一个问题可能是对的,但在这种情况下它不是。不是100%确定为什么会出现这种情况,但也似乎因为corrupted_array与一个已知的“快速”数组长度(分配它的长度1)。因为这个长度是不修改(修改一个界外写不算),engine总分配FixedDoubleArray后备存储器之前自己已知的偏移量。引擎可能已经在某处缓存了这个偏移量,但不完全确定它是如何工作的。需要知道的是,只要不通过JavaScript再次扩展数组的长度,将元素指针重写为NULL不会导致任何问题.
最后阶段
差不多做完分析了。需要解释的最后一行是:
1 | function trigger(array) { |
为什么Sergey选择在包装器数组中返回corrupting_array和corrupted_array? 如果只返回corrupted_array来试验poc,将注意到poc不再工作(corrupted_array的长度永远不会被覆盖)。
在GDB中快速查看一下。在GDB中使用–allow-native-syntax flag运行以下代码:
1 | function trigger(array) { |
注意到这里的区别了吗?用于corrupting_array的实际JSArray对象消失了!在这里,只有corrupted_array的后备存储区,在索引0和1处有[0.1,0.1],然后是corrupted_array的后备存储区,最后是corrupted_array的JSArray对象。因此,corrupted_array长度所在的越界索引, 现在位于corrupted_array的索引5,而不是索引7。仍然可以看到写越界的情况发生,但是下标是错误的.
在解释为什么用于corrupting_array的JSArray对象消失之前,重要的是要注意这个特定的场景仍然是可利用的。实际上,它用一个简单得多的语句替换了当前存在的看起来很复杂的return语句,从而稍微简化了触发器函数。只需要将x设置为5而不是7,同时将类型x作为范围(0,1).
还有一种可能的方法是这样做:
1 | function trigger(array) { |
修改乘法和减法,使能够将x设置为5,而输入者仍然输入最终的数学。如果尝试这个poc,将看到它确实有效,并为简化了return语句.
现在,为什么corrupting_array的JSArray对象消失了?也许它被TurboFan优化了?为了理解这一点,必须看一下最后一个优化阶段—逸出分析阶段.
逃逸分析
Tobias Tebbi有一个很精彩的演讲详细阐述了这一阶段, 简单地说,V8使用escape分析阶段来确定它是否可以优化任何不能从函数中转义出来的已分配对象。在这里,“转义出函数”只是指从函数中返回,可以通过return语句,也可以通过外部作用域的变量,等等.
在修改的poc案例中,TurboFan正确地推断出corrupting_array实际上并不需要分配。它只需要分配后备存储,在索引x处做一次越界写操作,然后就结束了。实际的corrupting_array不会在函数其他地方使用,也不会从函数中返回(因此也不会从函数中转义)。这就是为什么如果不从函数中返回corrupted_array,那么用于corrupted_array的JSArray对象就会消失.
如果在节点海图中查看这一点,只需比较负载消除阶段和逸出分析阶段的图即可。将注意到,负载消除阶段有一个额外的Allocate[Array, Young]节点,这个节点在逃逸分析阶段不存在。这是假定为corrupting_array分配JSArray对象的节点,并对其进行了优化.
与第一个POC相同的开发原语
前面提到过,只要稍微修改触发器函数,就可以从第一个poc中获得相同的利用原语。注意,在安装一节中,提到了一种无需任何编译器优化就构建release版本的方法。如果尝试在禁用编译器优化的情况下运行以下代码,则需要很长时间才能完成。如果想尝试的话,建议您编译带有编译器优化的默认release版本。
第一个poc的代码如下所示:
1 | array = Array(0x80000).fill(1); |
EXPLOITATION
这个bug已经有一个nday的漏洞由@r4j0x00所发现. 这还有numerous其它博客文章它描述了一旦实现了如此强大的利用原语,如何在V8中执行代码,所以不会详细讨论这个主题。从这个阶段执行代码可以使用的一般步骤列表如下:
实现addrof原语: 在corrupted_array之后分配一个对象,称之为leaky。将希望泄漏其地址的对象设置为leaky上的内联属性,并使用corrupted_array读取此属性的地址越界.
在32位的V8堆栈上实现绝对r/w原语: 数组有32位的元素指针。创建一个PACKED_DOUBLE_ELEMENTS类型的数组,该数组在堆上的corrupted_array之后存在。使用从corrupted_array的越界写入操作, 修改新数组的元素指针到任意32位地址。现在,可以使用这个新数组对V8堆中的任意32位地址读写64位双值.
在64位地址空间上实现绝对的r/w原语: V8中的TypedArray对象使用64位的后备存储指针。在堆上的corrupted_array后创建一个BigUint64Array,并使用越界写入corrupted_array修改BigUint64Array的后备存储指针到任意64位地址。然后可以使用BigUint64Array对任意的64位地址进行读写操作.
实现代码执行: 加载WebAssembly模块, 泄漏WebAssembly实例对象的地址,使用32位任意读原始泄漏特权页面的地址(存储实例对象), 特权页面中的代码替换为自己的shellcode使用64位原始任意r/w, 最后调用WebAssembly函数.
结论
真的很喜欢从根源分析这种特定的漏洞。个人了解了很多关于TurboFan的工作方式,以及如何通过滥用TurboFan中的类型来利用一个看似不可利用的漏洞。
希望这篇博文对你(读者)和我一样有帮助。如果你能走到这一步,感谢阅读这篇文章!
译自
- SIMPLE BUGS WITH COMPLEX EXPLOITS